|
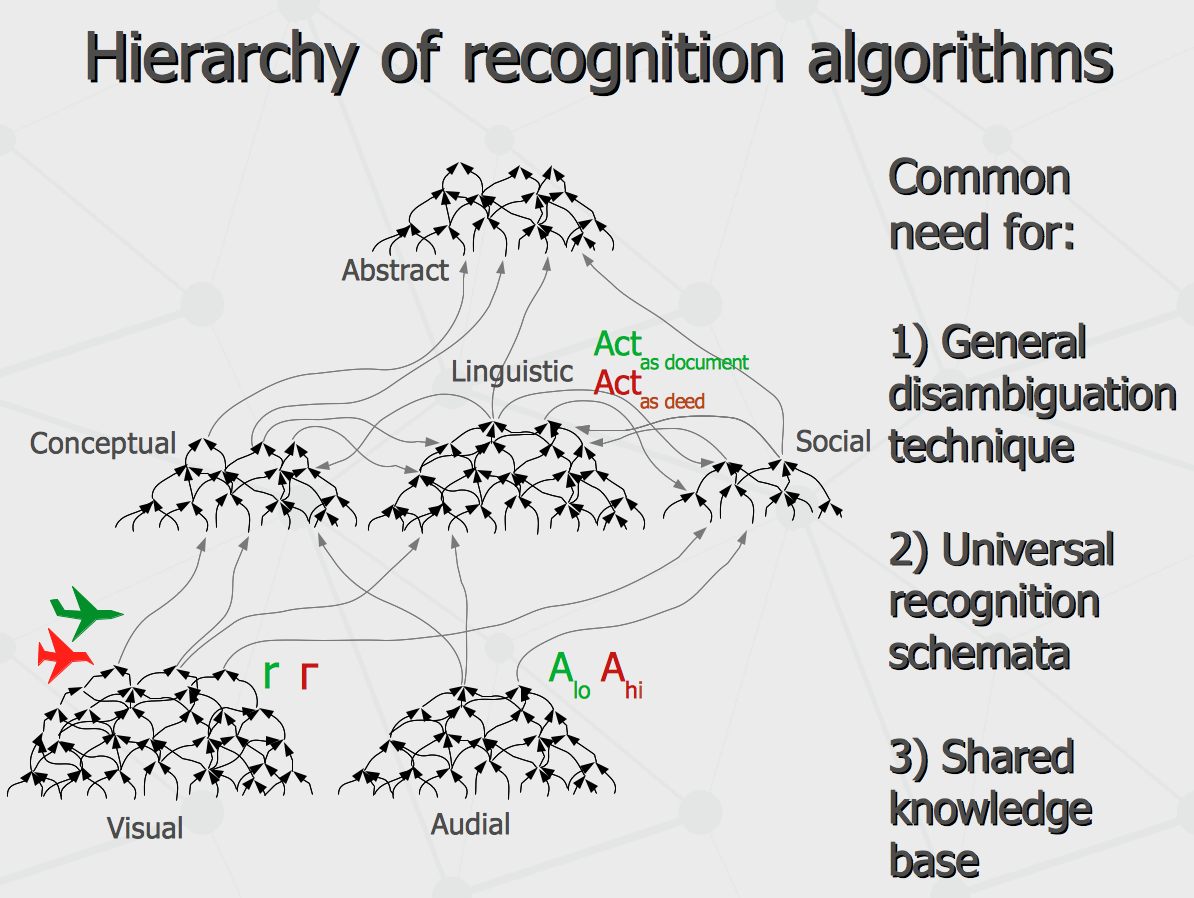
The Emerging World Wide Mind Anton Kolonin, 2013, August 1. Here is extended version of the talk that I gave at the Artificial General Intelligence conference. There is video variation of the presentation for wider audience available in Russian. Over couple ten years, I have had to do some pattern recognition applications. There were target tracking on video stream, optical character recognition, making sheet music out of raw audio and automatic text classification. Each time any development have been reaching some point where further increase in precision needed disambiguation techniques involving extra contextual information. For instance, one may need to consider sound to distinguish plane from bird, and consider periodic change of the pattern shape for the opposite. For another example, one would need to know language of a sign to identify its symbols correctly, and further know meanings of the most words in some sentence to comprehend a homonym word in this sentence. Similarly, in order to get the right notes for the sheet music from a polyphonic audio record, one would need to know the musical instrument playing. That is, it always comes down to the need of some disambiguation technique, involving task-specific contextual environments. Further, it gets to some universal cognition schemata, operating with different topological structures of patterns and contexts, specific to each task. Finally it ends up with a need for some shared knowledge base of possible contexts, including low-level patterns specific to the perceptual domain as well as higher level concepts involving multiple patterns, overlapping across multiple specific domains.
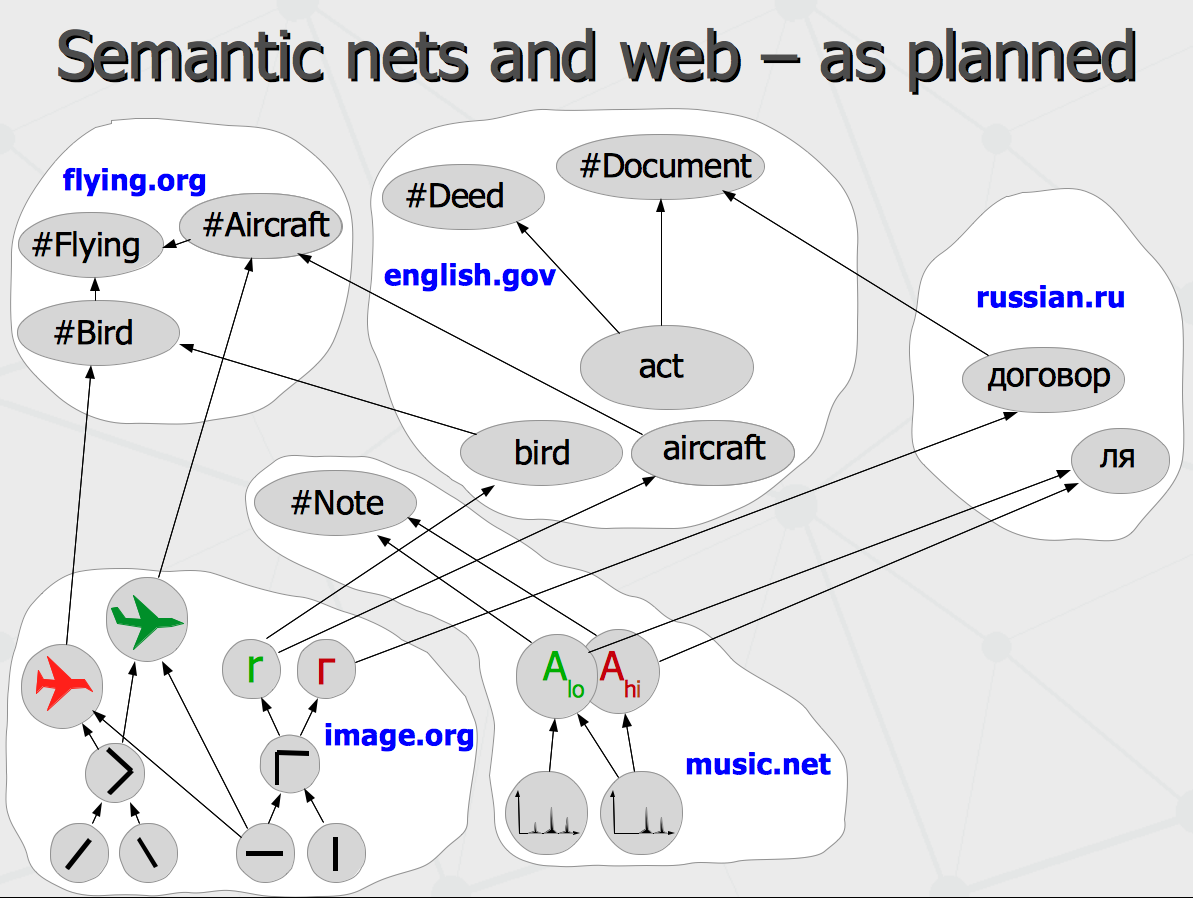
Effectively, that knowledge base is just a semantic network. In this network, the patterns on sonogram are linked connected to notes and letters, and elementary visual elements like wing or tail are connected together as visual symbols of birds and aircrafts. In turn, the concepts like a bird or an aircraft are connected to groups of interconnected letters representing words in different languages.
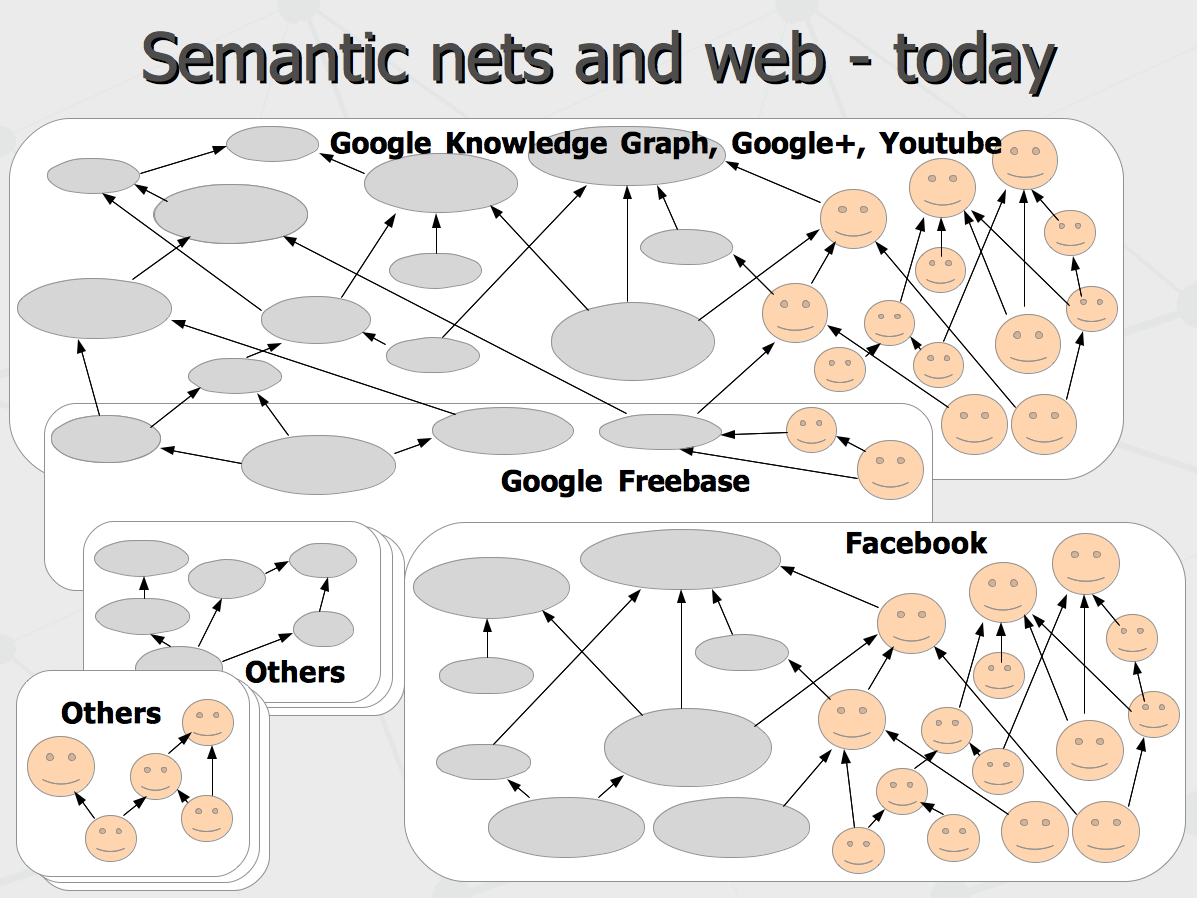
And then, different segments of that multi-level semantic network may reside in different segments of the distributed network over the internet called web sites, where each site contains the knowledge specific to its specialization. Which is what has been proposed as a “semantic web” – a world wide web of cross-linked concepts (and not just cross-linked text pages). It has been proposed about 20 years ago. Now, let us see where we have got so far. Attempts to create semantic networks hosting the entire common sense knowledge of a human being started about 30 years ago but the past year has made a leap. The Google Knowledge Graph has been launched and similar technology of Facebook is being announced. Most of the structured knowledge content in both systems is proprietary, but there is a Google Freebase data set which is made public and can be used as a common ground of basic common-sense knowledge. That effectively creates the environment for development of any intelligent applications sharing the common information and extending it with problem-specific data.
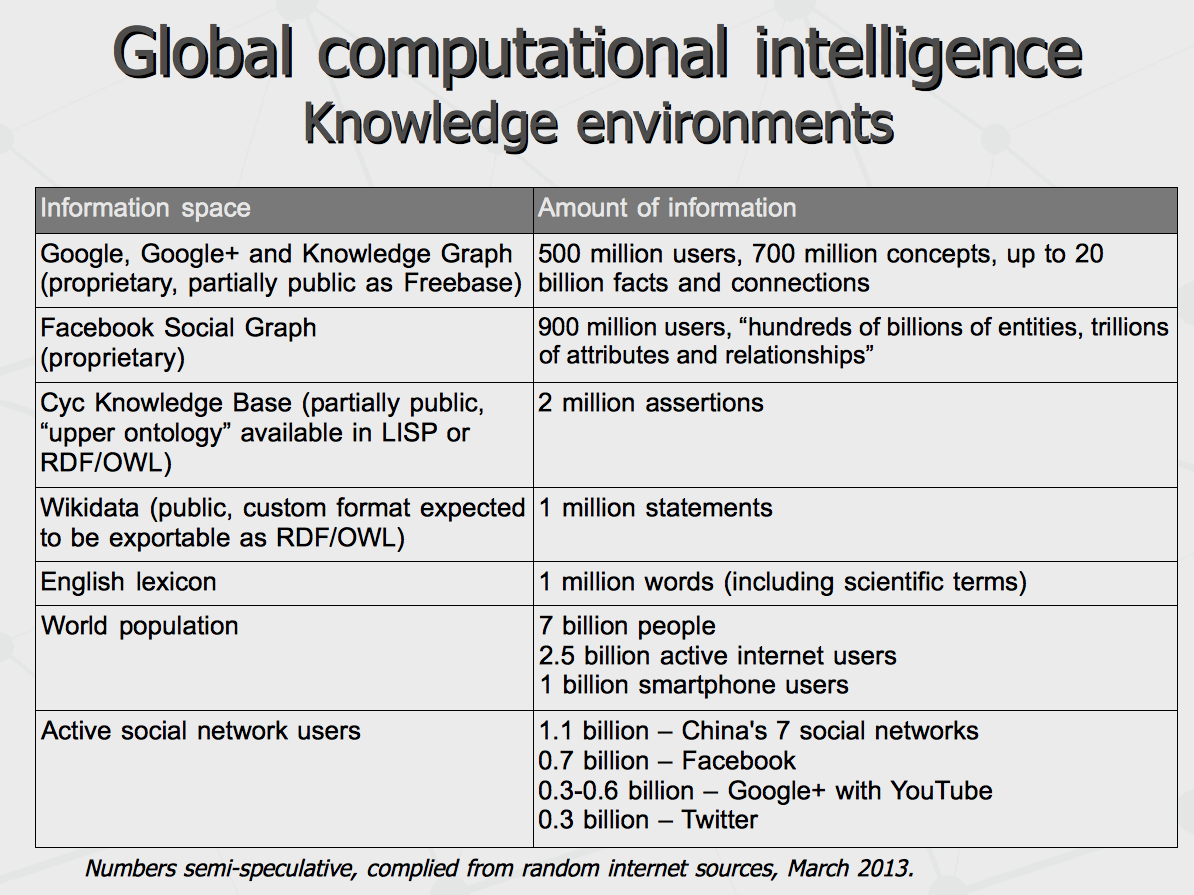
Let as take a closer look at the size and content of these knowledge networks. We can see Google and Facebook both are claimed to run the semantic networks of about couple billion nodes, with half of these nodes representing actual human beings in this world. To be cautious with numbers announced on the first two lines, need to understand that Google's numbers are actually backed with company dominance in the world search market, its Knowledge Graph publicity and support of Wikidata project over the year as well as acquisition of Freebase and quick growth of its content. The numbers given for Facebook sound more like announcements at the moment. Notably, that number of data has been accumulated in just few years. Before that, Cyc company being pioneer in this domain managed to raise just couple million nodes over almost 30 years. Take a look at the numbers of active internet and smartphone users. We can see about 20% of world population has been plugged into the network. Further, there is a potential of more than 1 billion users of 7 major social networks in China. Being consolidated in one network, that can outperform Google and Facebook by headcount. On the last side, Mark Zuckerberg have just announced last week to have 6 billion Facebook users in the next 27 years, having 5 of them connected with just any mobile phones. So we can observe the rapid growth of environment for world wide computational intelligence. And half of this environment is represented by digital identities of our human personalities.
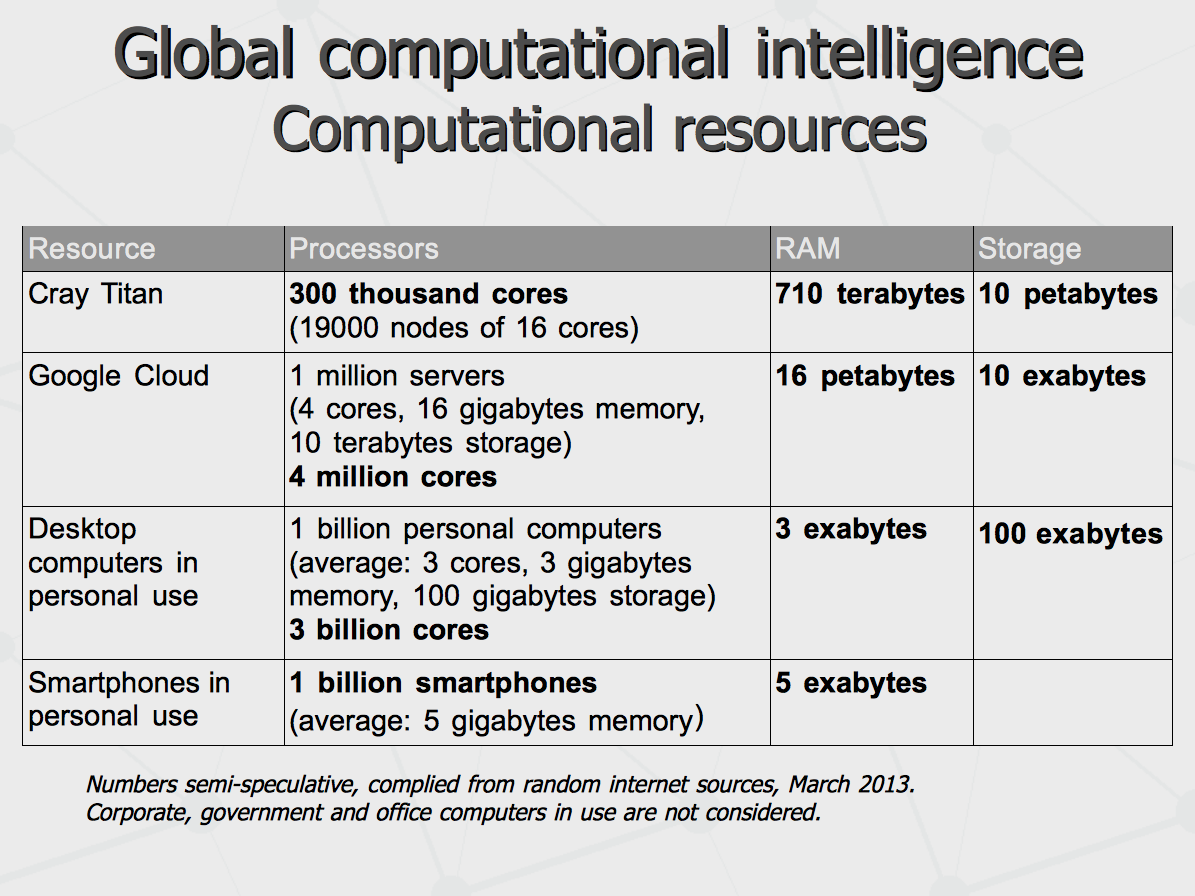
If such intelligence is about to emerge, let us see the computational resources it possesses for the moment. We can see the distributed Google Cloud (which can be running the Knowledge Graph) has roughly few orders of magnitude more power than the most powerful standalone super-computer. At the same time, there is much more power in the field out there, given total computational capabilities of individually owned devices, which provide another few orders of magnitude more. And the latter can be employed to expand intelligent computations from the cloud computers to world wide distributed computation network owned by entire humanity.
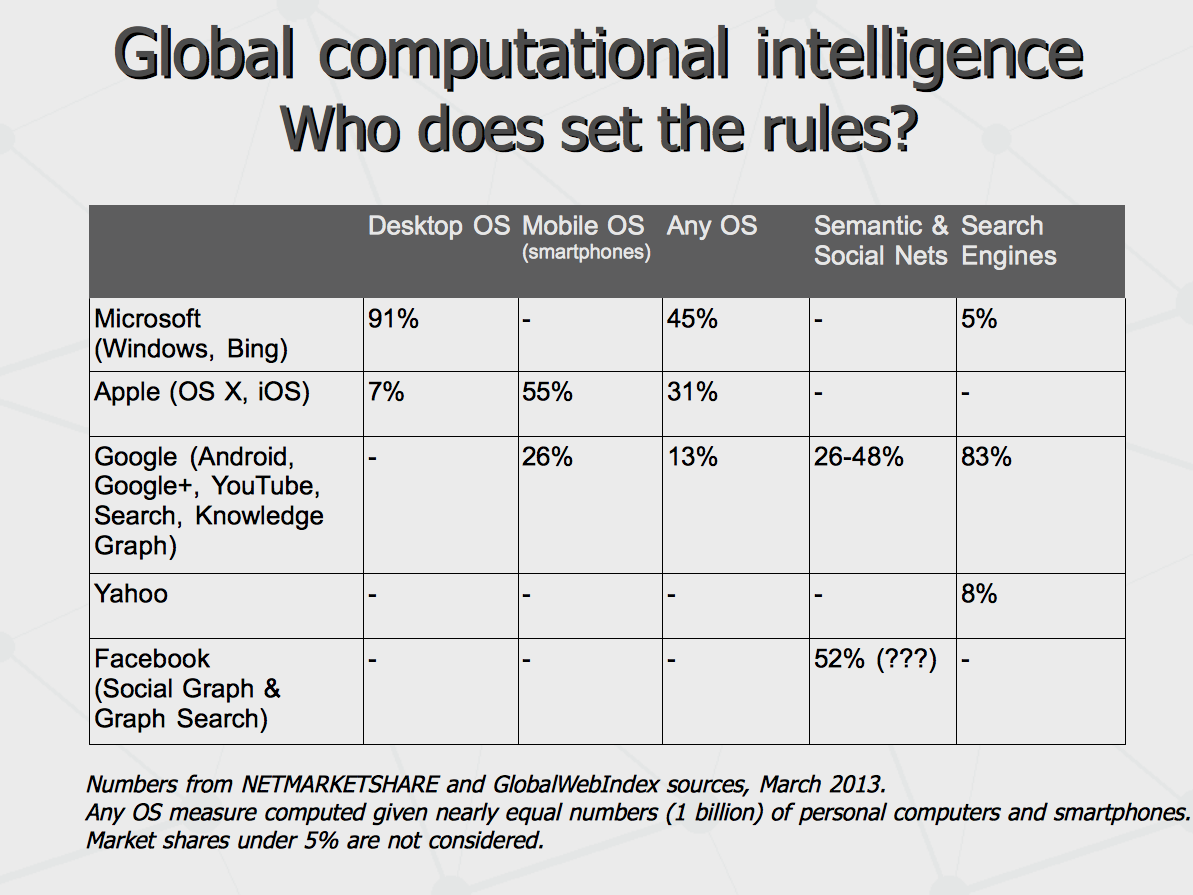
Well, Okay. Let's consider the intelligence is an ability to achieve complex goals in complex environments given limited resources (as put by Ben Goertzel). Thus far, we have the environment in place and resources limited so now waiting for the ability to achieve the goals to appear. But what the goals would be? To make sense of this, let us see who would make the rules. To great extent, these abilities can be implemented with software running on desktop systems powered by Microsoft, smartphone systems from Apple and Google, doing web search via Google, with knowledge graphs from Google and Facebook. Notably, Google has very good chances to to take it all over in one hands given the growth of its dominance in most segments.
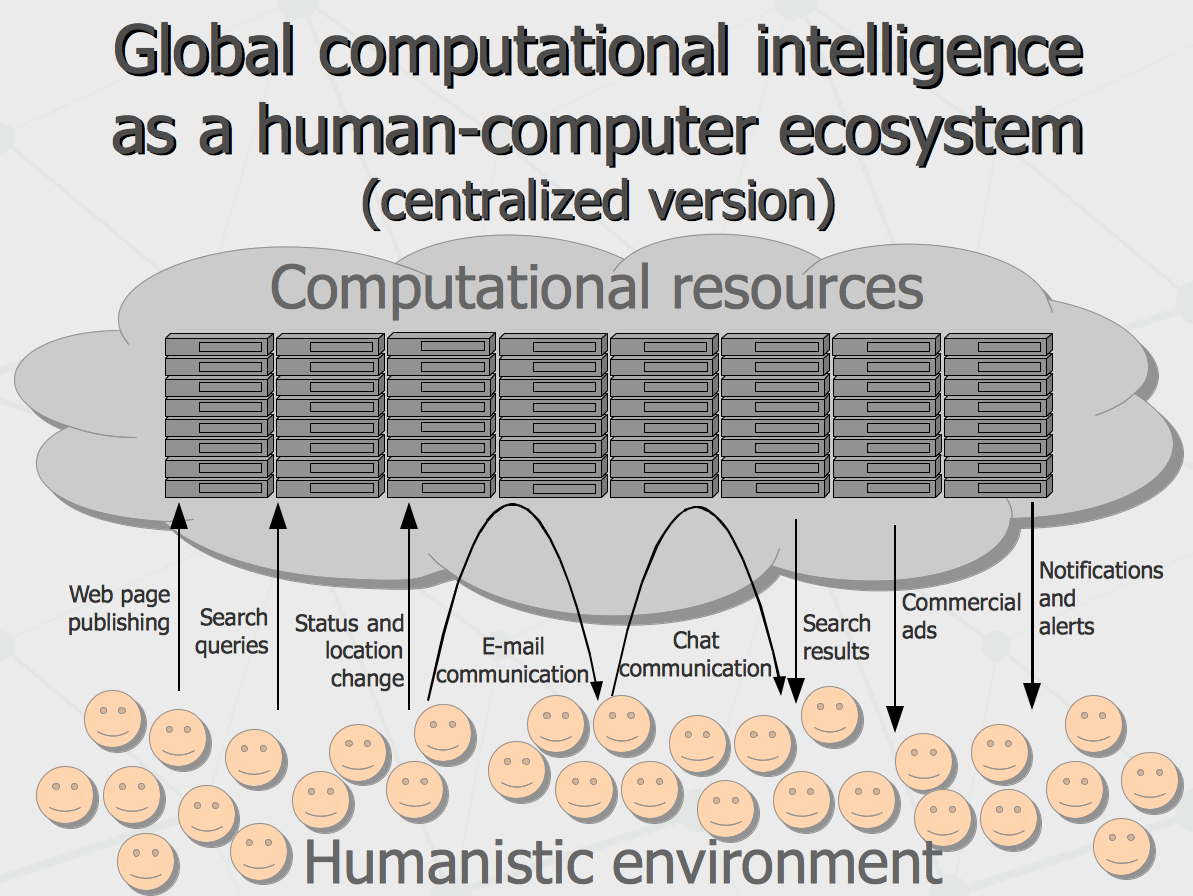
That is, what we see now can be thought as a human-computer ecosystem incorporating few billion of human beings serving. These billions of live nodes serve as a multi-channel sensor and motor cells working for the distributed computer brain. Just compare this to few hundred million single-channel sensor cells in human organism. As live sensors, we would feed the silicon brains with inputs of environmental, industrial, financial and political changes in the world. In return, we would be fed back with suggestions to invest in specific industries and stocks, get prepared to certain environmental changes and stick to some political vectors. This all would get powered with massive predictive intelligence techniques applied to global data of living world population. The most important question then is how the goal posing procedures would be set up for the intelligence of such system.
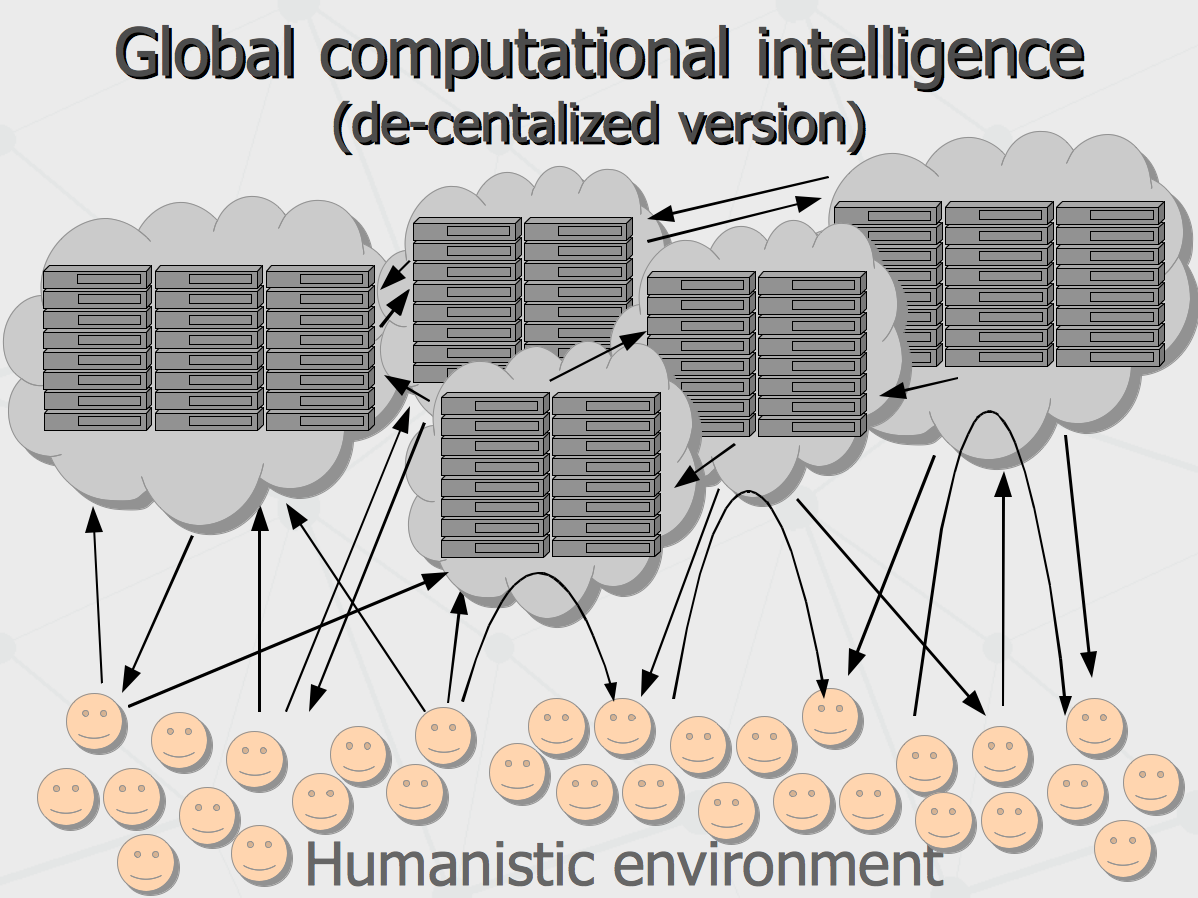
The approach currently being implemented assumes centralized globalization of the world-wide intelligence in single computer system (most likely, owned by Google) so the owner of the system would take care about the end goals and various constraints (such as ethical and political). The other option (less possible at the moment) is eventual emergence of concurrent global intelligence systems interacting in the same humanistic environment. The former would be one-truth-for-all kind of intelligence run by only one dominating system (like “Ocean of Solaris” anticipated by Stanislav Lem). The latter would be more like evolutionary competition to govern the human minds, performed by multiple artificial minds (and so different truths could be competing). The latter could be called as decentralized globalization of the would-wide intelligence.
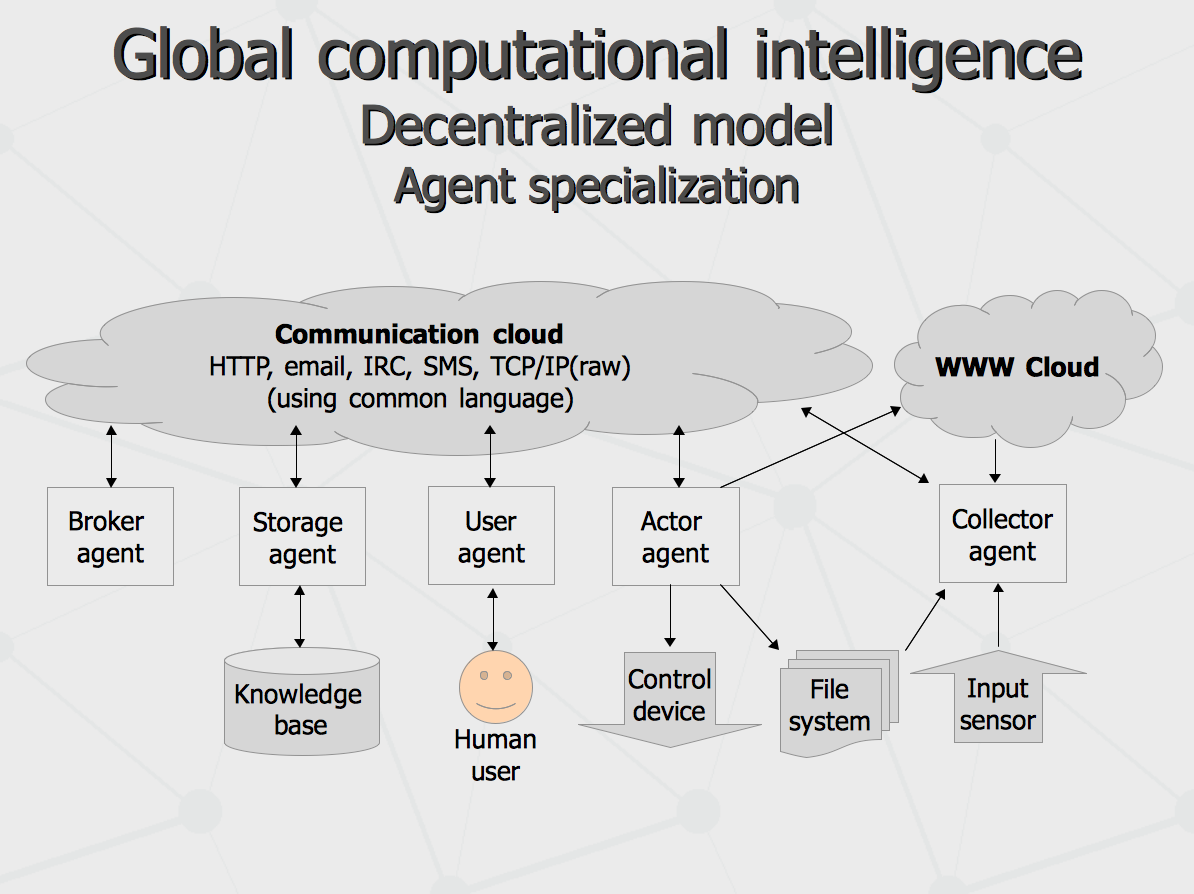
We can expect agents carrying that kind of distributed intelligence would support a number of functions or play number of roles. There could be Collector Agents collecting texts, image date from the web and data storage devices as well as video streams from surveillance cameras and numeric inputs from real-world sensors like say equipment of meteorological stations. Similarly, there would be Actor Agents performing actions toward surrounding world, like pushing various “red” and “green” buttons or making automatic web posts or generating some numeric data to be displayed on some monitoring devices. Of course, there will be User Agents intended for interaction with fellow humans with either conventional keyboards and touch pads or some novel devices like Google Glass or neurophysiological interfaces. For providing data access, there will be Storage Agents. Finally, Broker Agents would provide a way to build federated systems implementing one or combination of the roles in distributed manner.
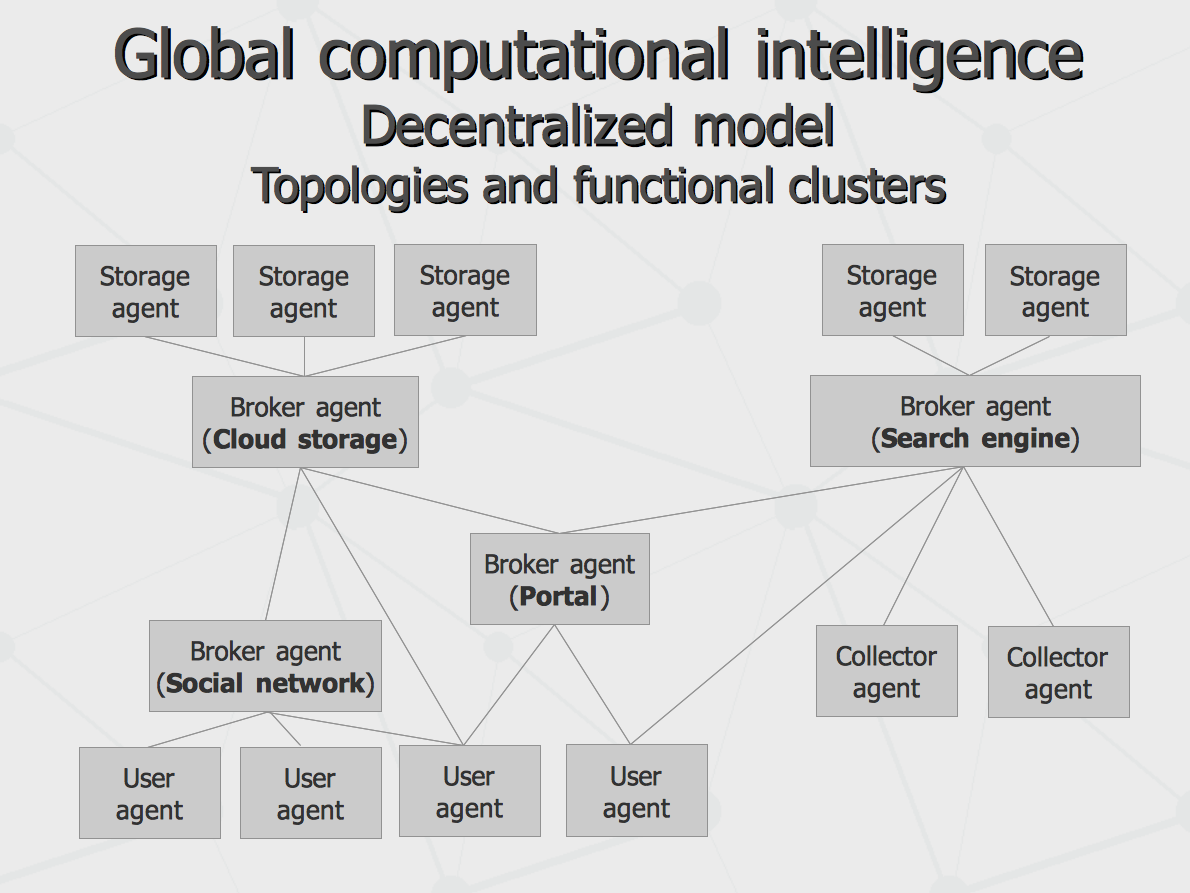
With the roles described above, multiple real-world systems could be implemented. For one example, Storage Agents federated with Broker Agent would build a Cloud Storage. For another example, combination of Storage Agents and Collector Agents could implement a Search Engine. Finally, federation of User Agents would build a Social Network while all of that connected together would build a Portal kind of functionality.
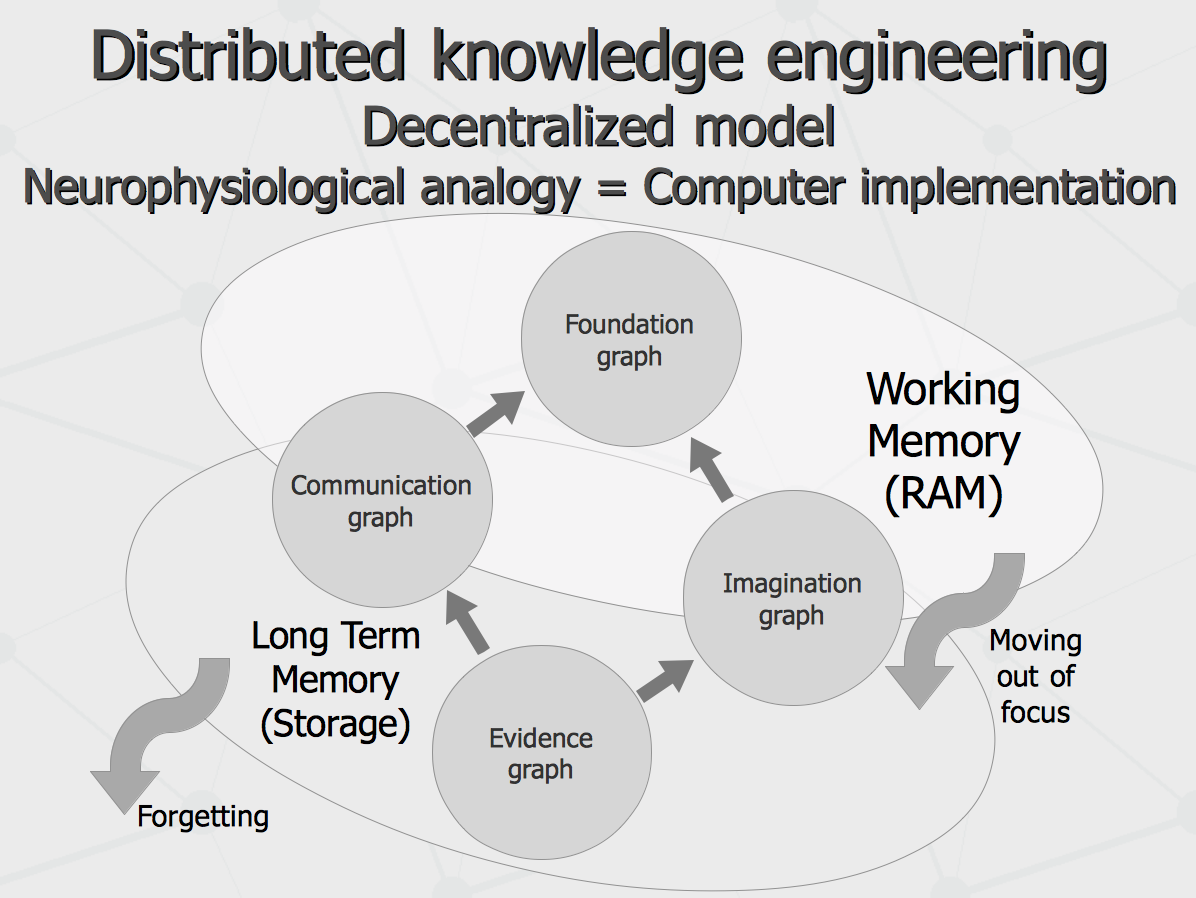
Let us try to look under the scull or under the hood of an agent, carrying this kind of distributed intelligence. There is a discussion on this that I have presented earlier. I just would note here, that suggested architecture would provide an architecture having quite sound neurophysiological analogy as well as transparent computer implementation. That is, Working Memory or Short Term Memory would keep most of the Foundation Graph (or Upper Ontology) as well as Communication Graph (keeping socially inspired weightings for the evidences coming into the system) and Imagination Graph (keeping current belief of the system as kind of “look-up table”). At the same time, limited amount of RAM available for doing high-performance operations with these graphs can be dealt with moving loosely important data out of attention focus, caching this data out to persistent disk storage. In turn, most of the long-term evidence data, available for full-blown “probabilistic” kind of inferences (with application of social weightings) could be stored consuming all of the allocated disk storage, unless it is overflown and so that data with low-evidence and importance can be “forgotten” to save the storage.
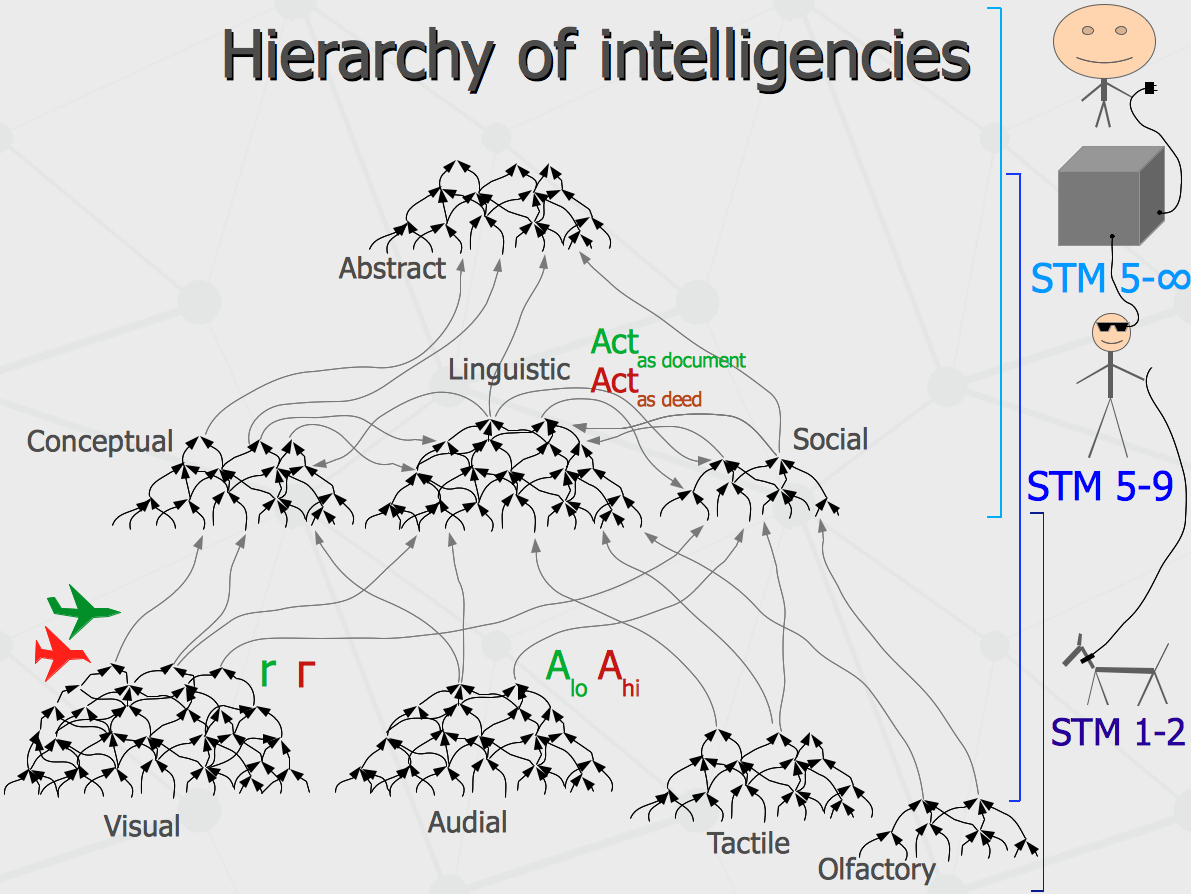
More from evolutionary perspective, the intelligence itself had appeared on top of different sensor and motor neural networks owned by animals with Short Term Memory (STM) size of 1 and 2. Later, it has grown up to human intelligence with STM size of 5-9 capable to perform linguistic and abstract reasoning about the real world objects and perform complex social interactions. By the way, some simplest cognitive capabilities (like olfactory) have degraded at this point. Instead of being able to perform them, humans established co-operation with low-intelligent animals, so that dogs with advanced olfactory perception provide the service for more intelligent humans obtaining stable food supply in return. In turn, the global artificial brain, given STM size higher than human possess, could deal with longer reasoning chains and think of higher-level concepts. And it could be co-operating with humans in real time via interfaces like Google Glass or some other physiological and neural interfaces coming in the future. That would be computational face of the technological singularity being forecast. However, there is a genetic singularity that could change the picture potentially, having human beings with genetically modified brains to take over the world-wide computer mind.
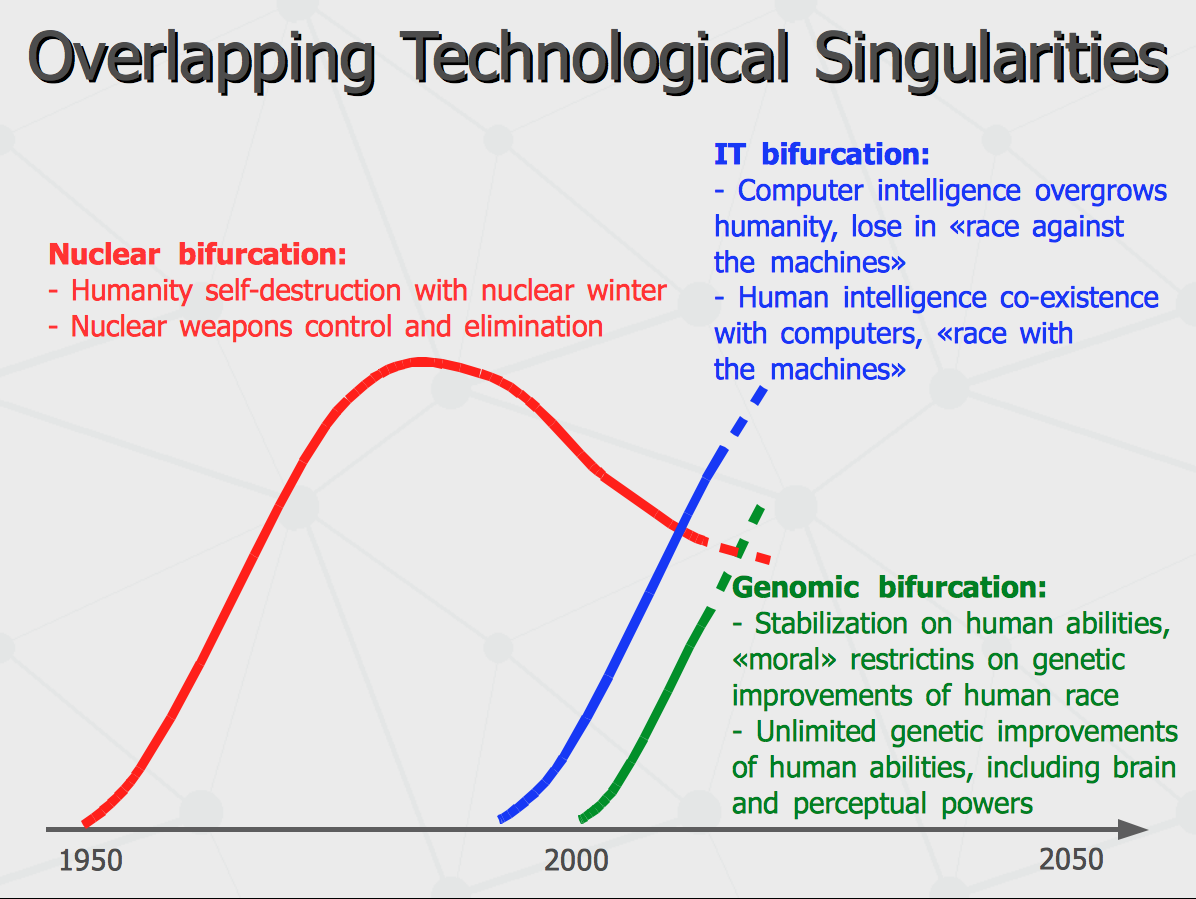
Indeed, there are few overlapping singularities having place at this time. The first one started with nuclear era which put the whole humanity into bifurcation point with two options: a) self-destruct in nuclear winter and b) keep to survive in strategic equilibrium between multiple owners of nuclear weapons. We all are still balancing on this edge. The second kind of singularity is one that we are talking about here and the options are: a) humanity to lose the evolutionary war in favor of "The Matrix" and b) humanity to customizes itself to "race with the machines", hand by hand together. And finally, advances in DNA sequencing and its possible practical implications open the doorway for modern eugenics. In simplest case, that would be screening embryos during in-vitro fertilization in order to select the most intelligent one to give a birth. Im more complex case that would be an instrumental and targeted change of the genome for larger Short Term Memory or better IQ on pre-embryonal phase. Obviously, both kinds of the research would get banned in most of modern Western countries due to religious and ethical considerations. However, it is certain that the same religious and ethical considerations would not let to terminate lives of such "super-babies" born in some other places where the religious and ethical restrictions are no that high. And then evolution of human race would run into another kind of evolutionary race...
Appendices by author:
Related resources: |