|
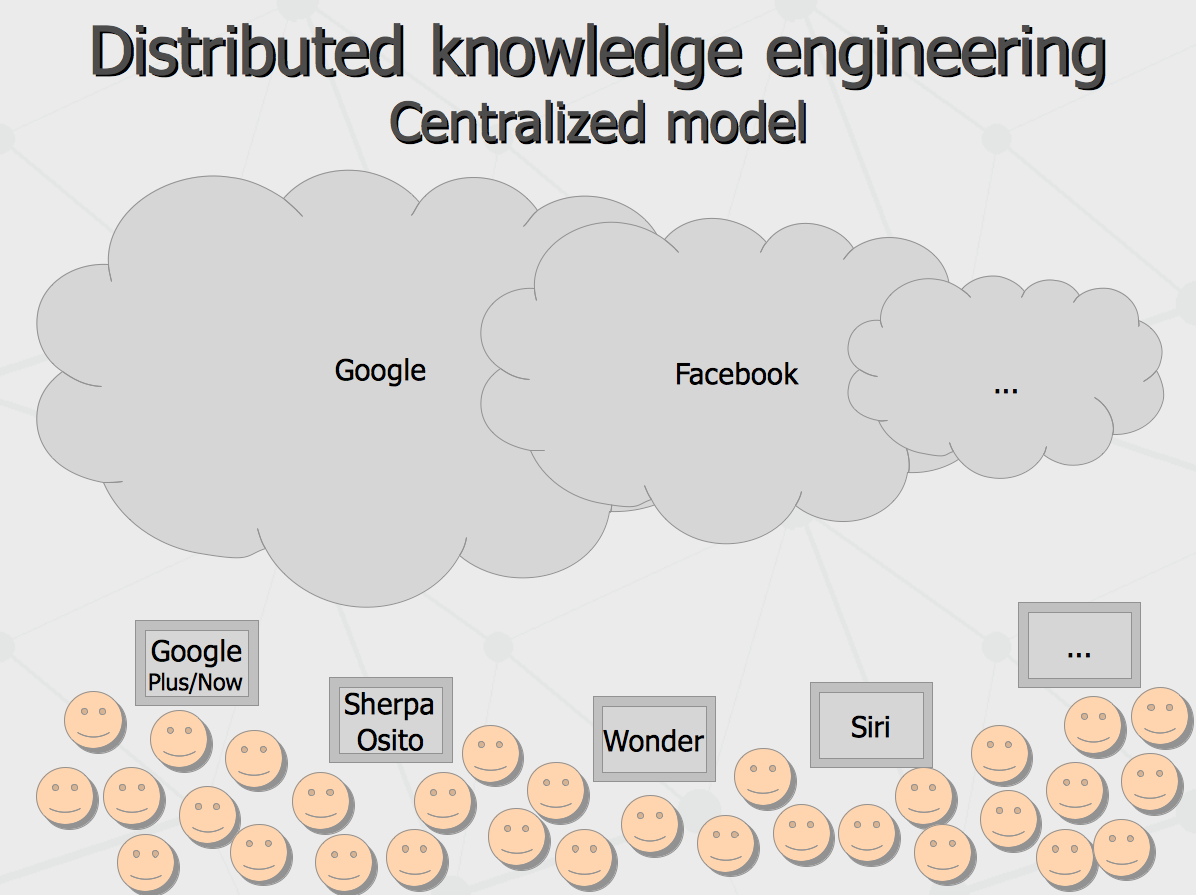
Distributed knowledge engineering (with Webstructor system) Anton Kolonin, 2013, May 10. Here is continuation of the talk about global computational intelligence given at Siberian forum «Industry of information systems» where I described what is the centralized globalization of structured knowledge and how it can be connected to emerging computational intelligence. On the next day, I have presented an “alternate” or “complementary” model – decentralized globalization of structured knowledge and have described one practical approach to it. Here I discuss the following topics. Paradigm of distributed knowledge engineering To get started, let us compare the two models. Within centralized knowledge globalization model, all information gets clustered within closed semantic databases owned by few largest knowledge aggregators with an access to it by means of so-called intelligent agents. In such a case, the vast majority of intellectual space gets closed in few data centers (even if few percent of it can be offloaded to clients as “public domain knowledge”). In such case, it is implicit that the central storage keeps kind of absolute truth knowledge about any event or entity in the world.
For the historical memory and sensory environment requirements mentioned above, there is a need to maintain (by public domain computer agents) an open space of semantic graphs which can be formed by means of sharing (donating) the personal semantic graphs by private agents, given each sharing or donation act contains information authored by an agent itself or delegated to an agent for re-distribution and it is considered non-confidential. Regarding the ability to expose the knowledge, per above, each computer agent can have a right to retain intellectual property on the knowledge they contribute (possibly in legal space delegated to the agent's hardware owner) and specify the privacy levels of it so it can be either accessible by peer agent only or forwarded to another agent. Possibly, there should be a way to explicitly specify access levels to particular agents or agent groups involved in global communication. The fertility of diverse behavioral patterns is obviously not that much a requirement but more a beneficial outcome from the other requirements. On the other hand, this would enable social regulation in “intelligent computer society” which is effectively ensuring open-ended development of cognitive potential of entire computer intelligence ecosystem. In turn, the responsibility for computer agent's actions reflects the fact that the end consumers as wells as action matter of computer intelligence are we humans. Given today legal practice, the responsibility for failures more often stays with hardware operators rather than software vendors. However, the more intelligent computers become, the more difficult situation makes itself. For instance, legal responsibility for viral software creation and distribution goes to software makers as soon as the software get installed on the victim's hardware illegally (i.e. without of agreement of hardware owner). However, if hardware is running software (from one source) deriving its actions from the knowledge (from another source), there may be a “binary weapon” effect when a harm is produced by combination of the two. Since such effects may be unpredictable (so one can't forecast the software behavior in advance), in addition to open knowledge transfer protocols there may get more demand for open source software distribution model with potential ability of a customer to perform an audit of the software they are about to delegate their corporate or personal intelligence to. In its turn, even the open knowledge content itself could provide be traceability to identify originators of any knowledge. Finally, by language we mean not just syntax of declarative descriptions of data sets or imperative programmatic instructions but whole range of means to convey the meaning of states, intents and inquiries of communication agents, based on common root ontology. Semantic architecture of a language, regardless of its syntactical representation (say same can be put in RDF or Lisp syntax) should support wide range of communicative paradigms to be conveyed, say:
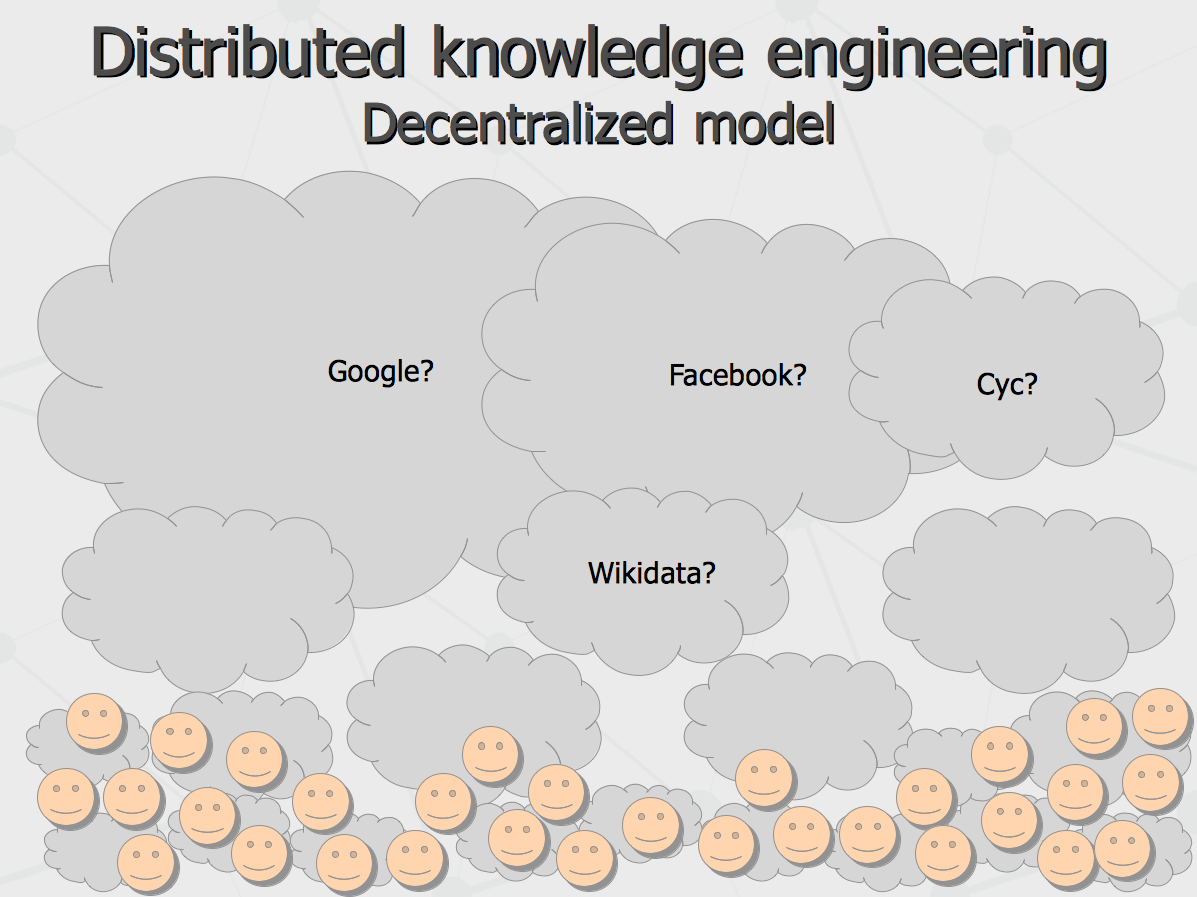
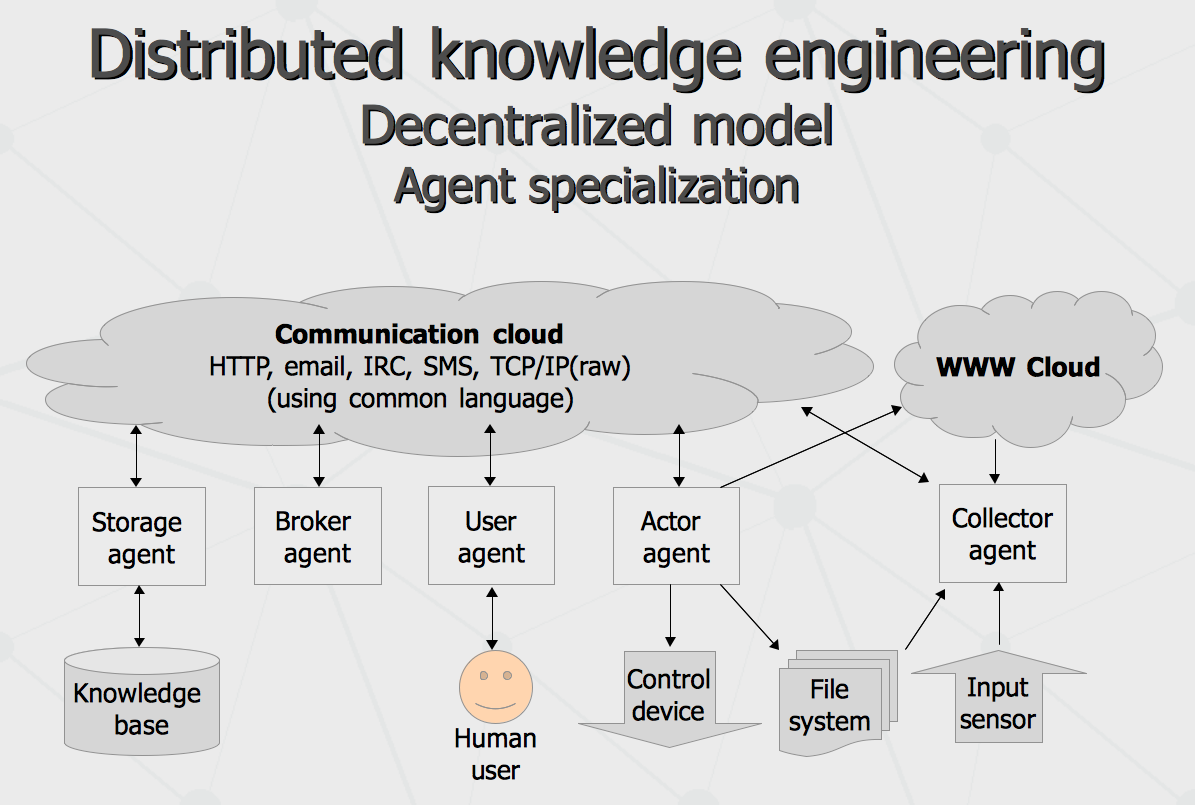
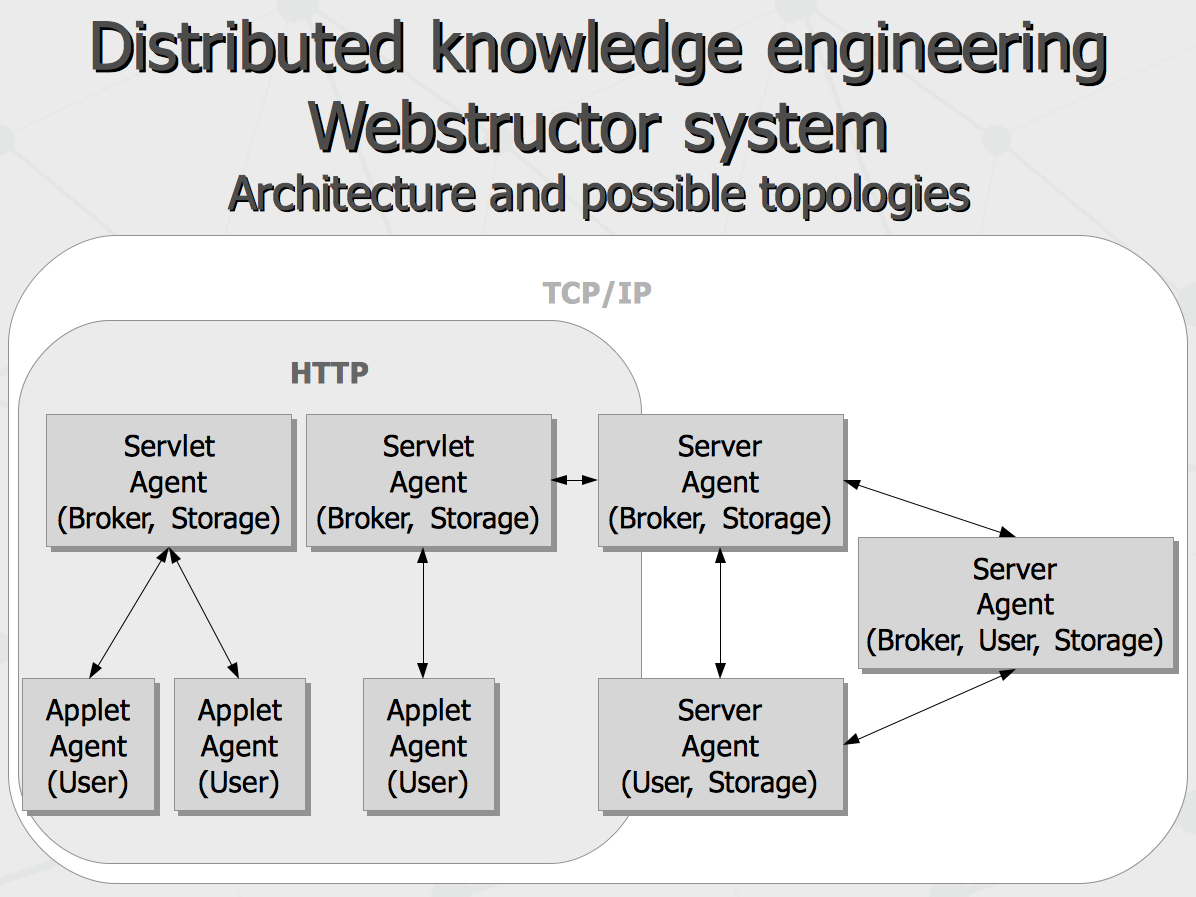
Another important properties of language necessary for social emergence of computational intelligence are fuzzy-ness, subjectivity and partial comprehension. While existing semantic notation schemas like OWL and RDF can be extended for it, some major players (like say Schema.org and Open Cyc) do not exploit this. From perspective of subjectivity, certain assertions can be treated useful only in context of particular belief system (say Google's belief in something may vary from same of Wikidata's). Regardless fuzzy-ness, it is typically not enough just maintain confidence level of fuzzy assertion, because the process of merging congruent assertions coming from different communication subjects do need evidence recorded in some way to come up with resulting confidence. Finally, partial comprehension means that any multi-part message from one agent to another may be partially comprehended, to the extent of overlapping mental models and ontological beliefs of sender and receiver, while the remainder of the message can be ignored. Besides expressional power requirements, the language also would benefit being easily comprehensible by human readers and writers, so that same interface for computer-to-computer interaction can be re-purposed by human peers. Overall architecture implementing the environment suggested above can be drawn with the following scheme, involving various agents playing one or combination of several typical roles.
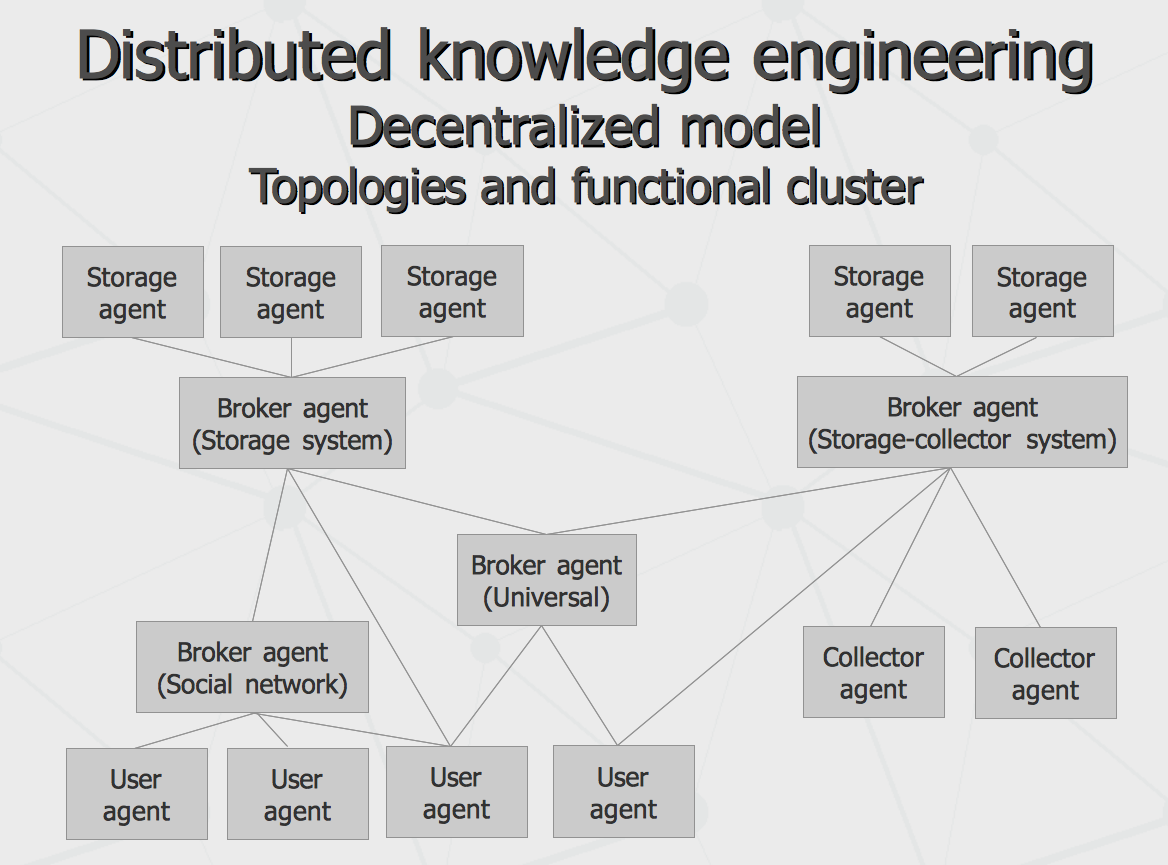
Different types of agents placed on the picture above are rather typical roles than narrow specializations, i.e. same physical instance of an agent can play different roles at once. At the same time, given specific storage and performance capabilities and connectivity graphs, various topologies can be formed (either by manual configuration or adaptive emergence), such as the following.
In order to achieve possibility of the described above, there seem to be a demand for developing open communication standard for agents of emerging computational intelligence, adopted by major software vendors at some point. That standard would include specification of interfaces the intelligent agents would support as well as language to be used for communication among them. The interfaces would include functions such as the following.
Notably, both interfaces would have synchronous as well as asynchronous versions – so that the output may be either given in respect to synchronous query, or it may be provided asynchronously upon prior “subscription” (with delivery of the data back using Input interface of the subscriber). Respectively, the Input can take form of a channel to accepts the data feed as well as a registry to list the data sources later polled via the Output interface of these sources. Given such interfaces, the social patterns of “intelligent computer society” would develop in different forms. The modern form - few “big” agents performing synchronous search/browse operations and asynchronous inputs (by means of crawling) - would be the one. But the opposite form – multiple “small knowledge businesses” (keeping the distributed content) would get synchronously polled by huge “aggregating businesses”, having necessary “public domain” data pushed to them in turn - would be also possible. With all possible forms of communication, the emergent formation of variety of hierarchical and network patterns would emerge in the cyberspace, evolving the most efficient communication (i.e. social) structures. On practical side, besides proposing the computer science community and industry leaders to come up with such open standard and language, there is a vision of a distributed computational intelligence agent software to run on every smartphone and personal computer, having that protocol implemented. The software would look like a Facebook or Google+ client (though different competitive implementations may appear given the same protocol), with some extra abilities like:
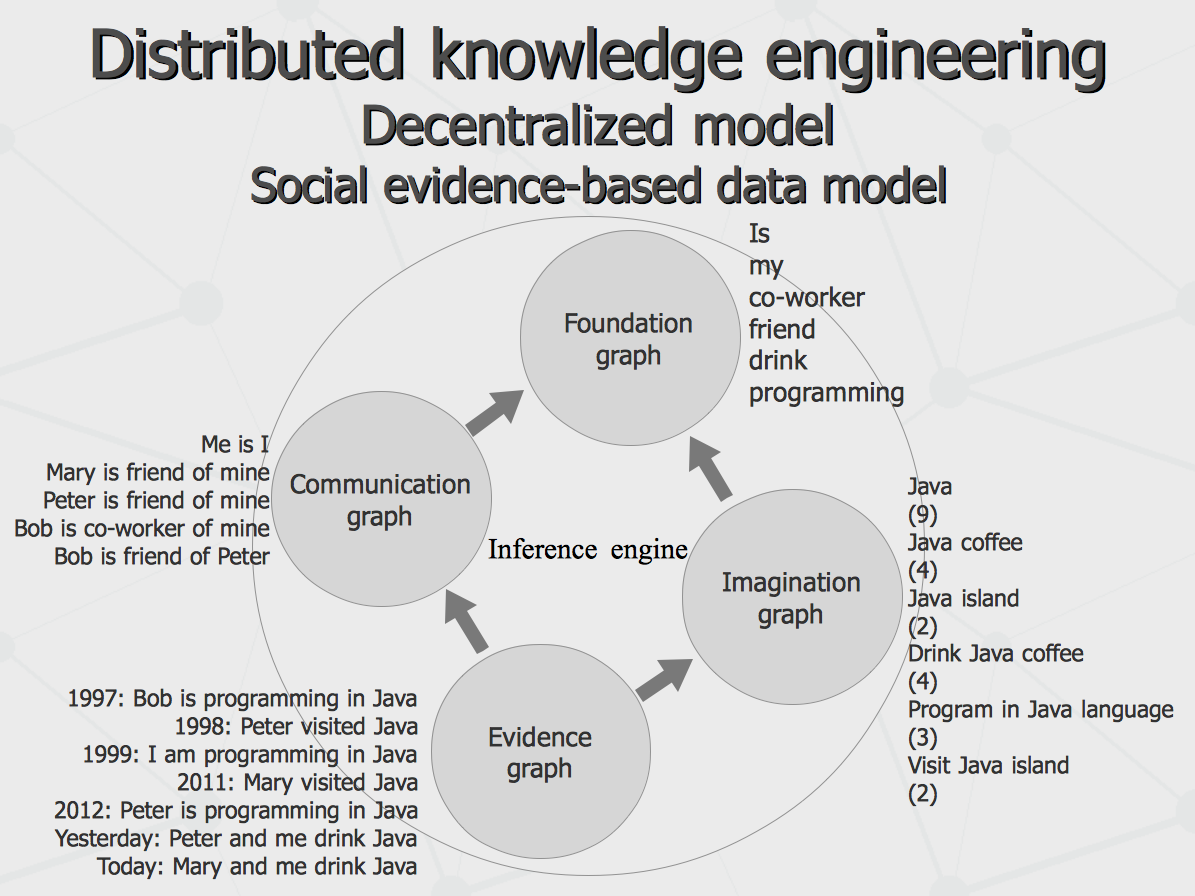
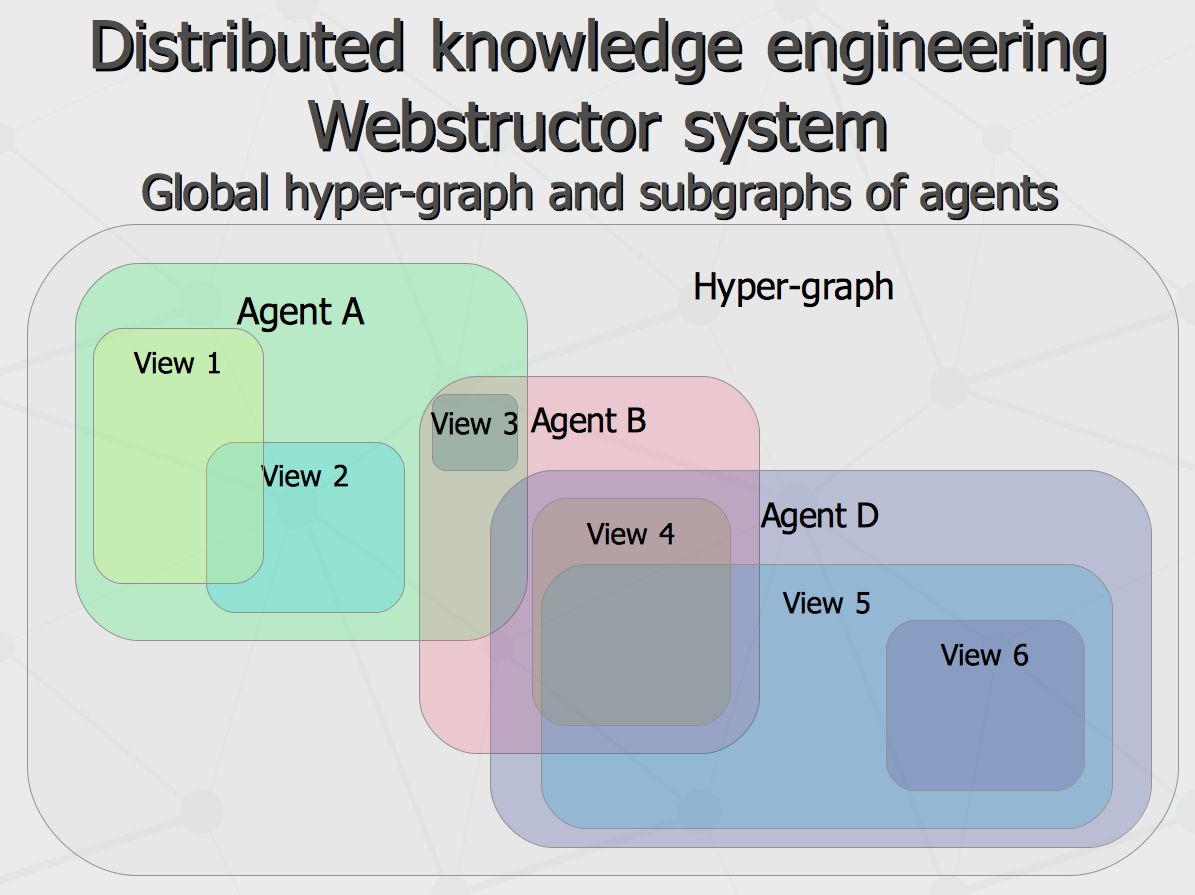
All that said, within the same communication infrastructure, such patterns as distributed storage, social network, federated search and others can be implemented. At the same time, topology of the communication graph can be not a schema “hardcoded by creator”, but rather an emergent structure being part of the entire system knowledge. Having all that picture of computational intelligence agent society drawn, the question arise – once the basic knowledge is uploaded, what is the role of humanity after that, besides operating the hardware running the agents, feeding them with the novel sensory inputs and sitting in the courts as legal representatives of the agents causing intellectual harm one to another? Well, there is still need for biological brains to come up with more fast processors and cheaper memory, as well as invent more efficient inference engines for newborn agents. And of course, it is assumed that, with all that environment provided and resources involved, there are the goals to be posed by someone. One of the major benefits of having the global computational intelligence emerged on the ground of distributed agent system rather than inside one or another private supercomputer farm (even given public access to it) would be possibility to have truly democratic mechanism of goal formation for the entire system. That is, the overall goal of the network would be some non-linear superposition of the goals of each society member, accordingly to the amount of quality of knowledge the member contributes to the society and the trust society gives the member in return. As a whole, such decentralized model seem to be more stable evolutionary than centralized one, since the latter can be biased not only by business and personal reason but just because of taking some non-evolutionary path at some point. Knowledge representation model As long as any agent talk to any other one same communication language, internal design of an agent, set of algorithms implementing each one and programming language used for agent implementation do not matter than much. However, there is one major principle to be followed. Even given variety of agent specialization, besides using common communication language on itself, agents are implied to have some jointly shared system of fundamental knowledge (belief system) regarding surrounding world and themselves. They should also have a mechanism of either acceptance of knowledge coming to an agent from its outer world (if it is compatible with agent's belief system), or rejection of it (in the opposite case). Further, for different sorts of accepted knowledge, an agent should be able to make judgments regarding reliability of different facts, which can be done given number of evidence associated with these facts, with account to trust in respect to knowledge sources communicating them. Here we come to social evidence-based knowledge representation model and notion of partial comprehension. With massive distributed data processing and many-to-many style replication, synchronization of concurrent changes (especially, such as updates and deletes) become a big problem. For instance, if agent A communicates fact P to agent B while B communicates fact Q to A, there is just a counter addition of information to each of the agent's knowledge bases. However, there is a typical scenario where agents argue “about” something, making conflicting changes to the same data. For instance, agent A tells there are relationships X and Y between P and Q, while agent B argues there is Y and Z but not X – who is to be trusted in such case? Obviously, both can agree on presence of Y, while X remains as personal belief of A and B keeps believing in Z. That is, assuming part of the message can be accepted and the reminder can be declined, it can be possible to make each of the agents more knowledgeable in the course of communication, yet not having to destroy belief system of each of them. Within the social evidence-based knowledge representation model, truth value of any piece of information can be calculated as sum of truth value of its evidence records communicated by peer agents multiplied by trust levels for each of these peer agents. To achieve this, the entire semantic hyper-graph representing knowledge of an agent can be split in four major sub-graphs, like shown on the following scheme.
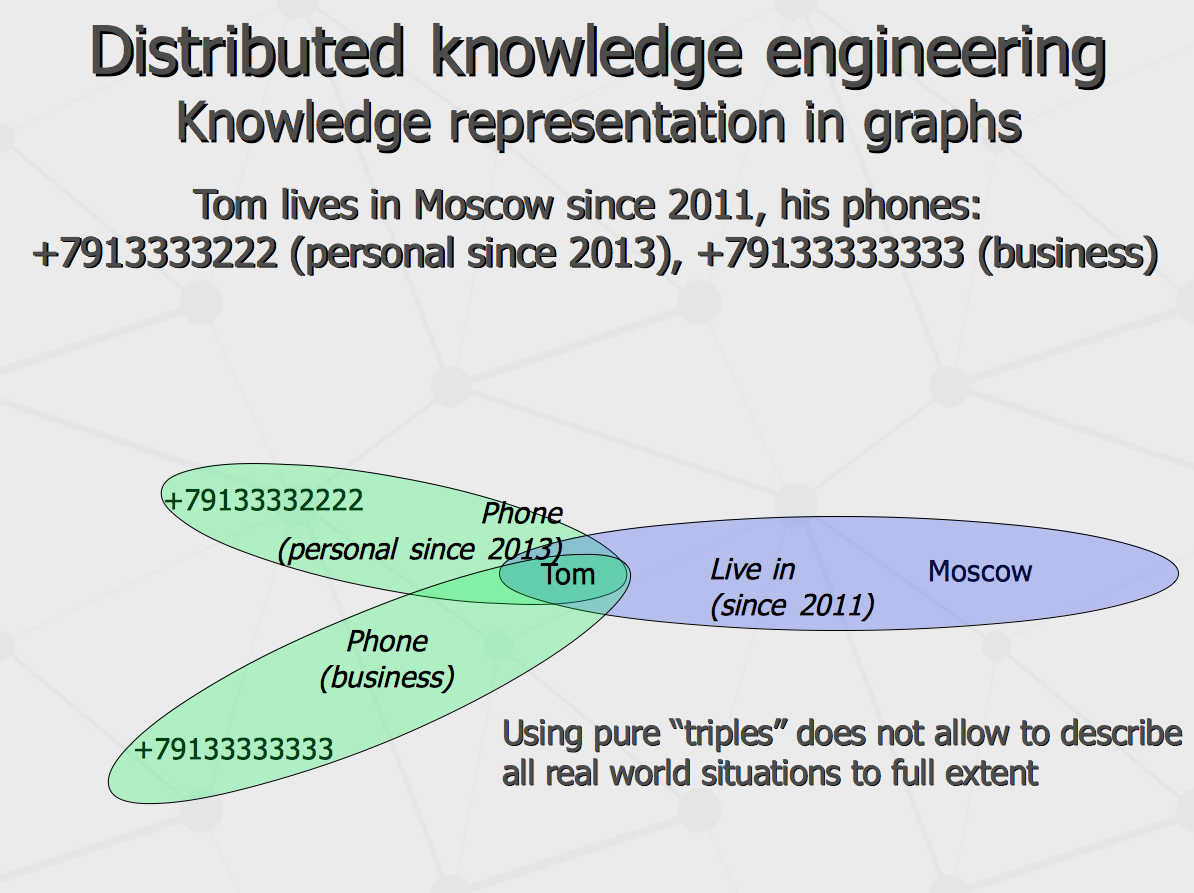
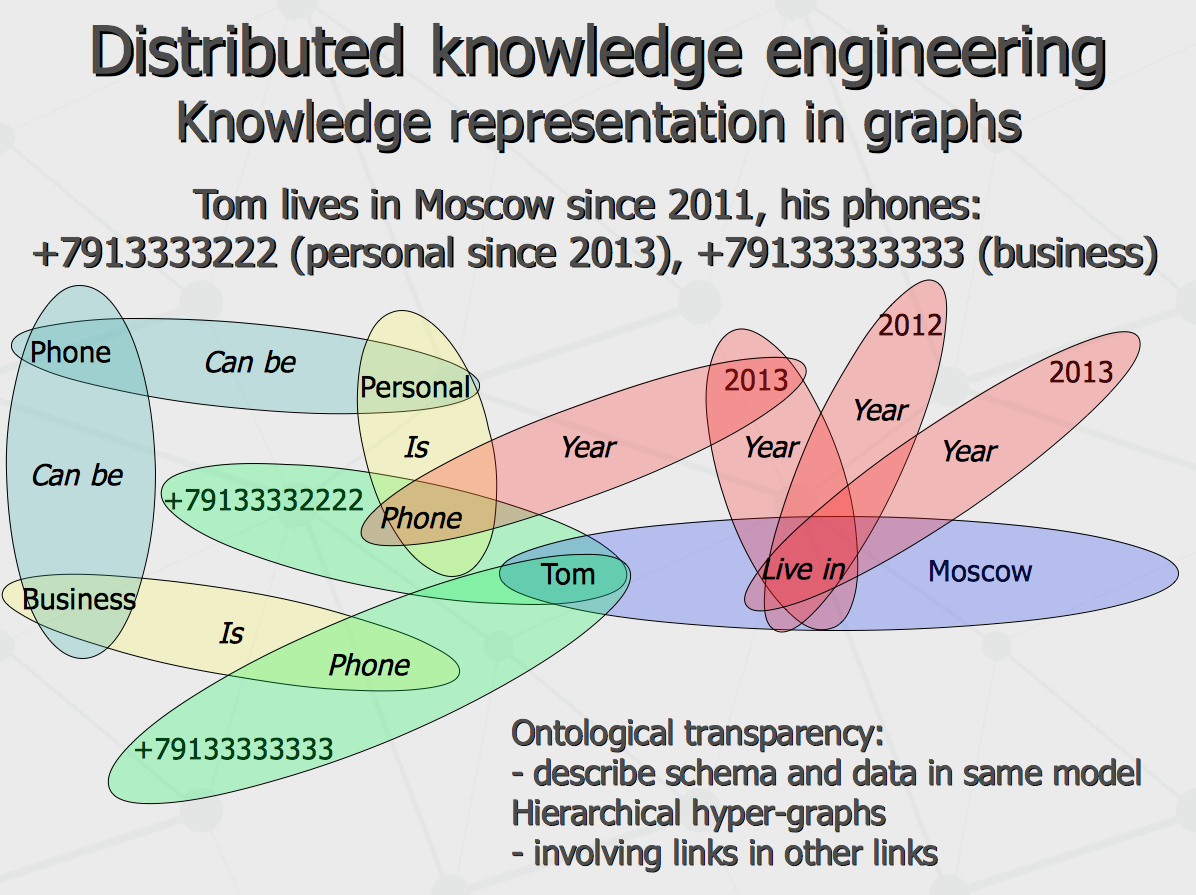
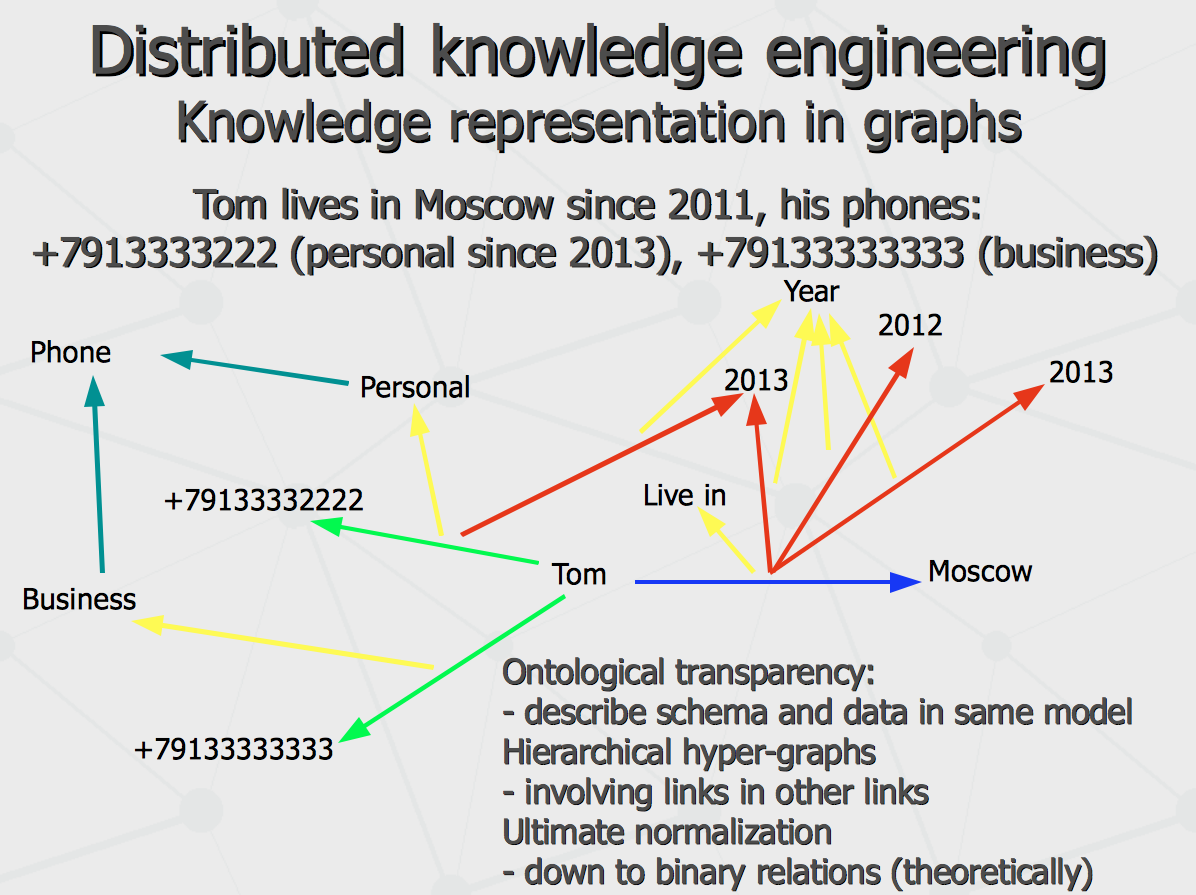
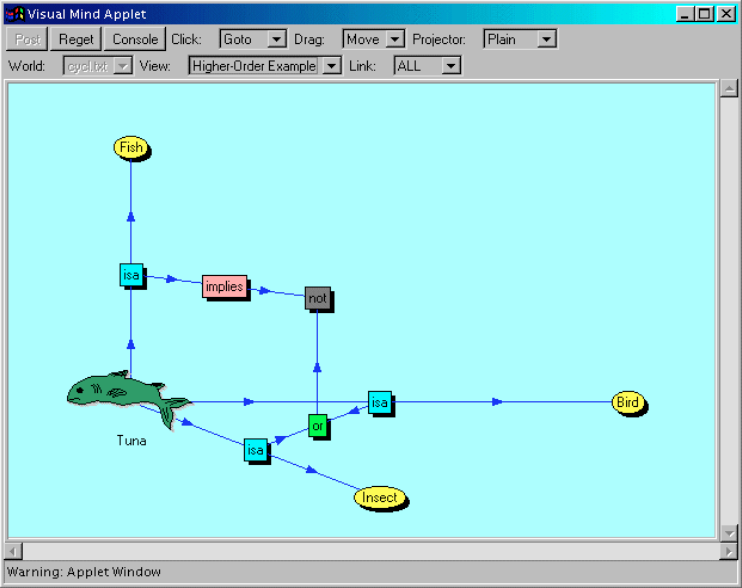
Further, let us consider structure of knowledge representation in the agent's graphs. Traditional approach to express semantic graphs (semantic networks) is to use ternary relations or triplets. They can be successfully used to describe something simple like «cat is an animal» or «Roosevelt is president». However, triplets are hardly applicable to express more complex information involving conditional, subjective and temporal contexts, like «in his childhood, Bob thought that even eating really too much ice-cream will never cause being cold». Thus, more complication to triplet-only schema is required, like shown on the following schema.
The Webstructor project on itself has been developed by me to serve as a proof-of-concept tool for the development of some of suggested concepts, taking it roots from the following history.
Current implementation model is simplified to such extent, so that only fundamental graph and communication graph are present – which implies a full trust communication model for agent's interactions, assuming any data involved in exchange is an absolute truth.
Implementation of the system implied exchange of information using either public HTTP or secure HTTPS on the web or using raw TCP/IP within private corporate network. In both cases, mentioned protocols were used as transport layer for direct conversions in object-relation language (ORL) between agents.
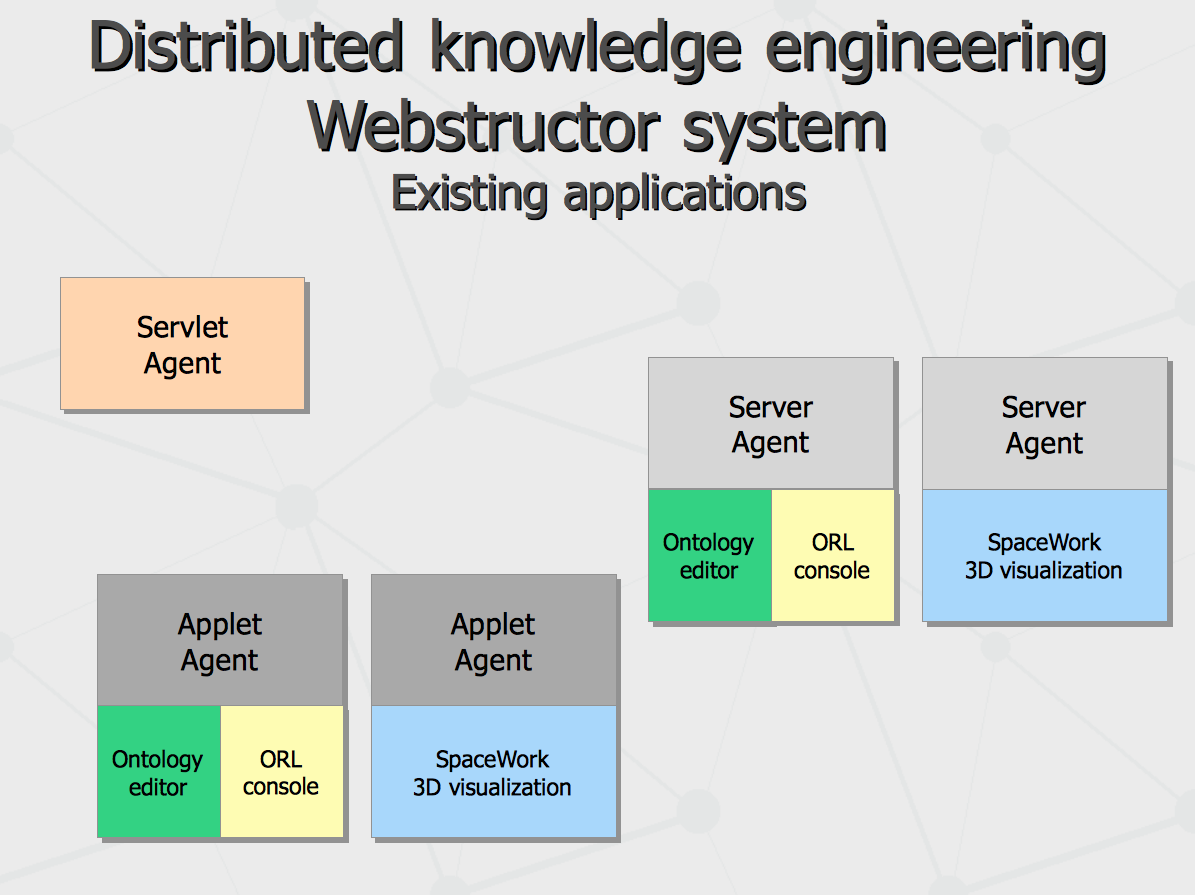
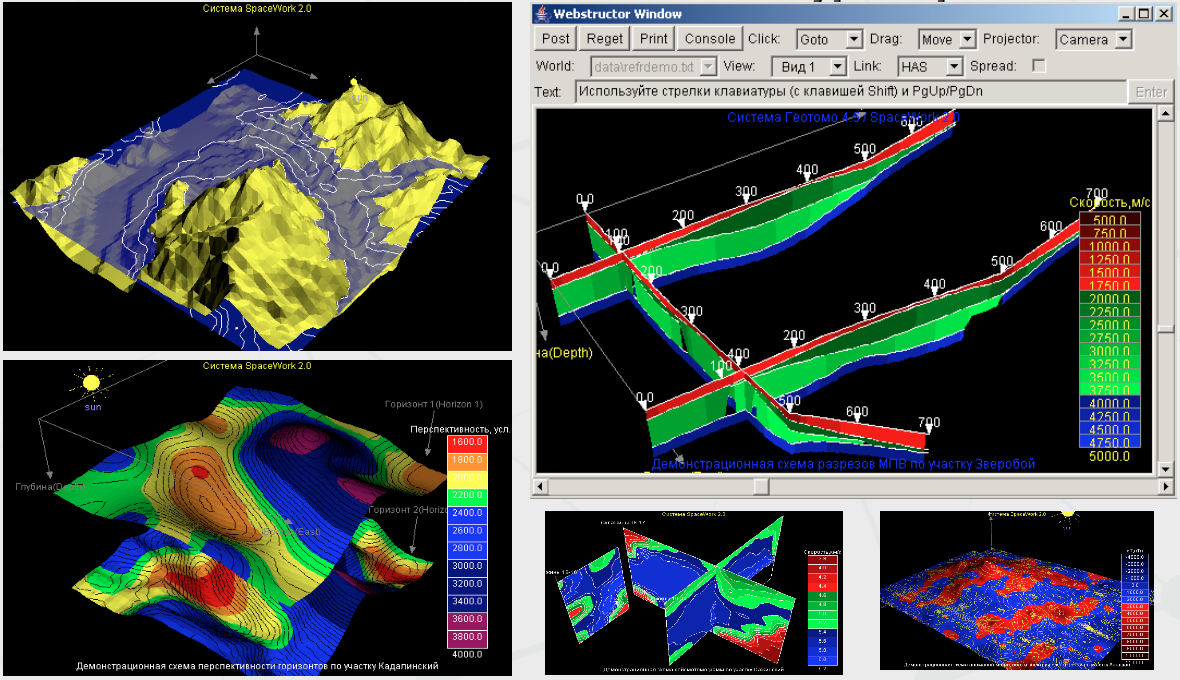
Within described architecture, there are two practical applications created – visual ontology editor and spatial data visualization system.
Ideas regarding 3-dimensional visualization of knowledge data, having local subgraphs projected to separate views, led to implementation of full-scale application intended for multi-dimensional visualization of complex scientific data on the platform of distributed information sharing. On the basis of Webstructor technology, Space Work visualization system has been designed and implemented.
The ORL language intended for communication between agents is meeting most of the requirements described in the first section of this article (as of today, besides explicit support for fuzzy-ness and subjectivity). Originally, it has been designed as compact notation of arbitrary structured data, including formal logic rules, declaration of business processes and arbitrary functional graphs. The following principles has been put into foundation of the language.
For instance, natural language expressions given in the former section can be translated to ORL as shown in the table below.
Essentially, most like XML and JSON and to some extent LISP, ORL does not rely on particular set of keywords but rather provide general semantic, syntax and punctuation regulations. Compared to basic XML, it is more compact and much more readable by human (yet a bit more hard to be verified by machine). Compared to LISP, it has richer punctuation syntax like different delimiters used for plain arrays (lists) or associative arrays (property sheets) and different brackets used for AND-style or OR-style boolean expressions, which makes it possible to represent structured queries in relational style, referring to classes of objects as SQL tables. The important feature of the ORL is its ontological transparency, so metadata and data are described in the same language (unlike any conventional programming languages and XML-DTD schema). That is, for instance, quite different object systems (i.e. relying on different “upper ontologies”) have been implemented in the works of 1997-1999 and later in 2001-2006 – using the same ORL linguistic processor model. At last, the key distinguishing feature of the ORL is built-in notion of structured query used to refer to objects “by conditional query” instead of referring to them say by pointer or resource identifier. Effectively, expressive power of ORL query is equal to one of SQL (assuming groups of knowledge objects inheriting sets of properties from the same parent class are corresponding to rows in some table of relational database), while groups of conditions joined by OR and AND operator are explicitly grouped by syntax (different kinds of brackets). This is very unlike RDF/OWL syntax which is referring to objects by literal resource identifiers. It allows to perform group operations involving attributes and methods specific to subset of some class instances. Also, it turns into powerful instrument for building flexible knowledge structures connecting “abstract” entities such as sets of objects qualifying the query condition at a time in a given semantic graph.
Our current work is dedicated to complete full specification of the ORL. Another goal is implementation of another generation of the agent software in the scope of Webstructor project (such as lightweight personal data sharing applications for private social networks or personal news aggregators). The purpose of the software would be open peer-to-peer network for personal knowledge interchange and collaborative intelligence evolution in society, including human individuals and computer agents. This would involve full implementation of social evidence-based knowledge representation model (including hyper-graph of subjective-temporal sub-graphs) and support for multiple languages used for referring to entities by name. That would require system-level support of categories such as time and language at system level.
Appendices by author: Related resources: |