|
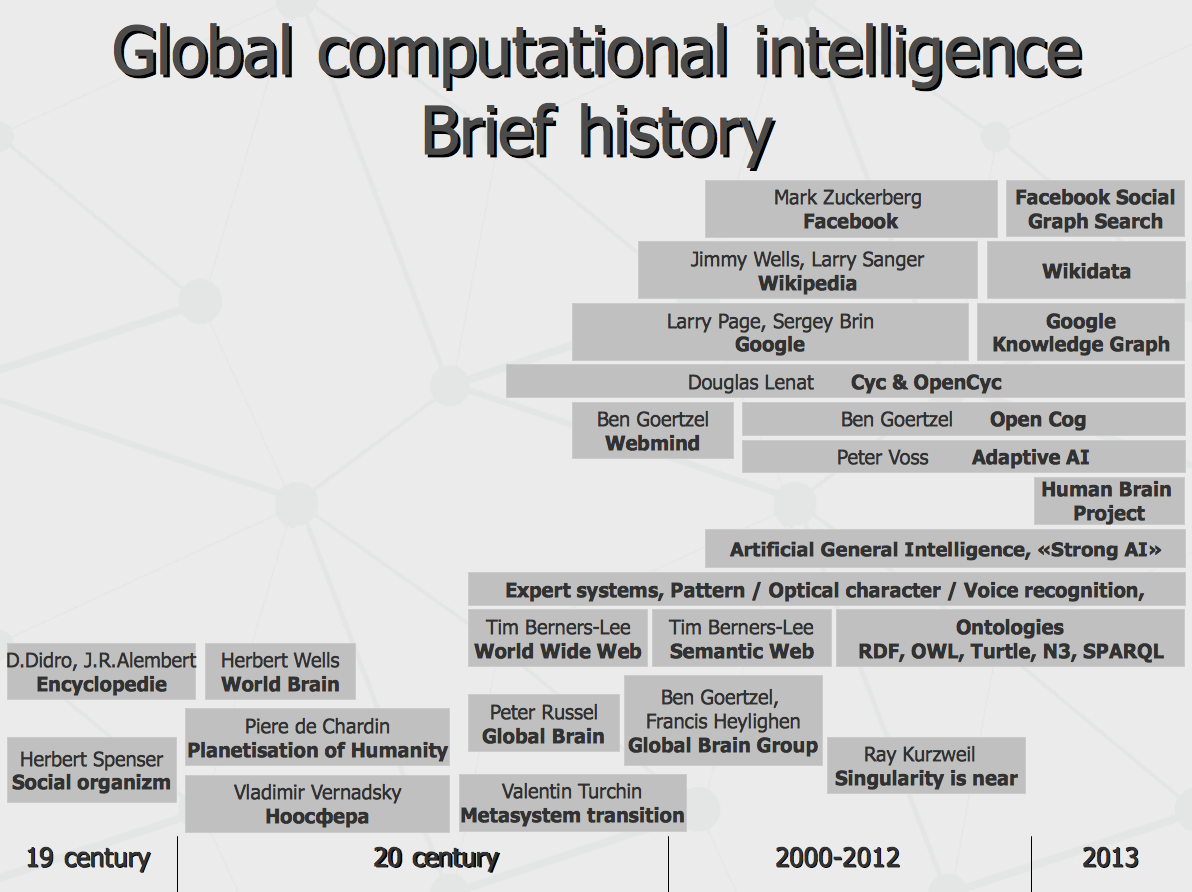
Global computational intelligence State of affairs, treats and opportunities Anton Kolonin, 2013, May 5 Last month, at the opening of Siberian forum «Industry of information systems», I have made presentation on the topic that I am following for more than 15 years. I have decided to do so due to the fact that this area of human activity has experienced a burst-like development during last year. Moreover, in the next few years, it may change our everyday life at least to same extent as it has been done earlier by personal computers and Internet. First – a bit of history. The idea of world wide intelligence has its roots in 19th century, when D. Didro and J.R. Alembert suggested to create world Encyclopedia. In the same century, the concept of society developing as single social organism has been proposed by Herbert Spenser. In the beginning of 20th century, the notion of distributed World Brain has been introduced by Herbert Wells in form of system of multiple Encyclopedias, covering different areas of human activity and knowledge. Nearly at the same time, the idea of noospherе has been developed by Vladimir Vernadsky and planetary role of human intelligence has been described by Piere de Chardin.
On somewhat more practical side, World Wide Web has emerged from concepts introduced by Tim Berners-Lee who later suggested another kind of web – Semantic Web, linking meaningful concepts instead of raw text pages. Later, this provided foundation for development of multiple applications and technologies in the area of semantic databases and knowledge management involving platforms such as RDF/OWL and others. On the latter wave, US company called Cyc, partially with help from some DARPA projects, has managed to build the world largest semantic database by the beginning of 21st century. Everyone knows the story of Google, Wikipedia and Facebook. It is interesting that, about 10 years ago, one of Google officials has been asked about the company plans related to semantic search and answered like there are no such plans – since conventional text search works well enough. And now, in less than one year, here is chain of events, including full-scale launch of Google's Knowledge Graph and later rise of if its competitive peer – Graph Search at Facebook. Let us make some definitions. Given definition of intelligence by Ben Goertzel, let us consider global computational intelligence as “the ability to achieve complex goals in complex environments, using limited resources”, given essential humanistic environments of today computer systems along with computational resources present in the world. Regarding the goals – specific goals of a free being are typically offered and constrained by environment. However, if an intelligence carrier has some master (or an operator, like in case of computational intelligence), the goals would be pre-defined by the master or operator themselves. In such case, intelligence criteria might not be necessarily judged by Turing test (which means a computer system can be thought intelligent if its spoken communication abilities are not distinguished from human ones). This is because the environment and goals of single human mind and global computational intelligence are not the same and so the underlying mental and cognitive models may be quite different. In former case, few hundred million sensor cells are getting one-channel audio, visual and tactile inputs from physical world in order to detect treats and opportunities for a live being. In latter case, few billion live sensors (represented by online users) are providing complex multi-channel inputs used to detect treats and opportunities for global intelligence system or its operator. Typically, opinions in respect to possibility of global computational intelligence can be split in four groups such as a) it is impossible, b) it is possible under certain circumstances (like purposeful help from humans), c) it is inevitable and d) it is already here. Leaving out the option for self destruction of entire earth-life-human-computer ecosystem, I would agree on transition from c) to d) is happening as we speak, with current level of emerging global neural system comparable to one of some simple animals. Which goals can be pursued by such a huge animal? Unless it takes total physical control over its computational resources, it must serve its masters in order to keep it plugged-in. So primary principal goals would serve the operator's interests. First one would be detection of treats and search for opportunities, enabling system and its operator to keep operating and expand its dominance. Next goal, as matter of purposeful activity of a system, operating in the environment of user mass, would be directing the mass to move somewhere, stimulating demand for some goods, services or political vectors – for system or operator benefits. Besides that principal goals, there is a technical goal to keep the system in symbiosis with the environment. In practical terms of today, that means satisfaction of search queries directed to the global computer system by users, which is required for the system to be demanded by its users (serving the system's sensor cells in turn). To achieve this, few things are required. First of all, there is a need for deep (true) understanding of the search query text, in order to process the query at the level of concepts, categories and relationships, rather than literal string tokens or keywords. And that is not just a matter of making search handy for user. Ten years ago, working for one of the companies developing kind of semantic search engine, I have had long debates with our product manager explaining him, how nice the graph search is working given the initial concepts precisely selected (via user interface) by user. In reply, I have been explained that typical call center operator has just limited number of seconds to handle the incoming support call so there is not much time to mess with mouse locating concepts for the search in multiple checkboxes or drop-downs. Indeed, what they need is just ability to quickly enter the search query in the text-box (or speak it out aloud, as speech recognition of today makes possible). But then, computer system has to be able to extract these concepts from the raw text doing what is called natural language processing (NLP). What means the system should be able to pass kind of reverse Turing test – being able to understand human speech as it were machine-friendly (rather than making the machine friendly for human). In turn, true understanding of the natural language needs account of user context. Obviously, the same question like “where to get Java?” can be handled differently. In one case, computer system may recall that previous queries from the same user were about Bali and Thailand so the person needs some idea regarding vacation on tropical island. In another case, the system may capture the GPS location of the user's smartphone as office of some software company, then consider time being office hours and so decide the user is looking for downloading latest Java software. In the third case, Google Glass may have pattern recognition detecting a rack in supermarket store and so the user could be told the number of row with different sorts of coffee in that store.
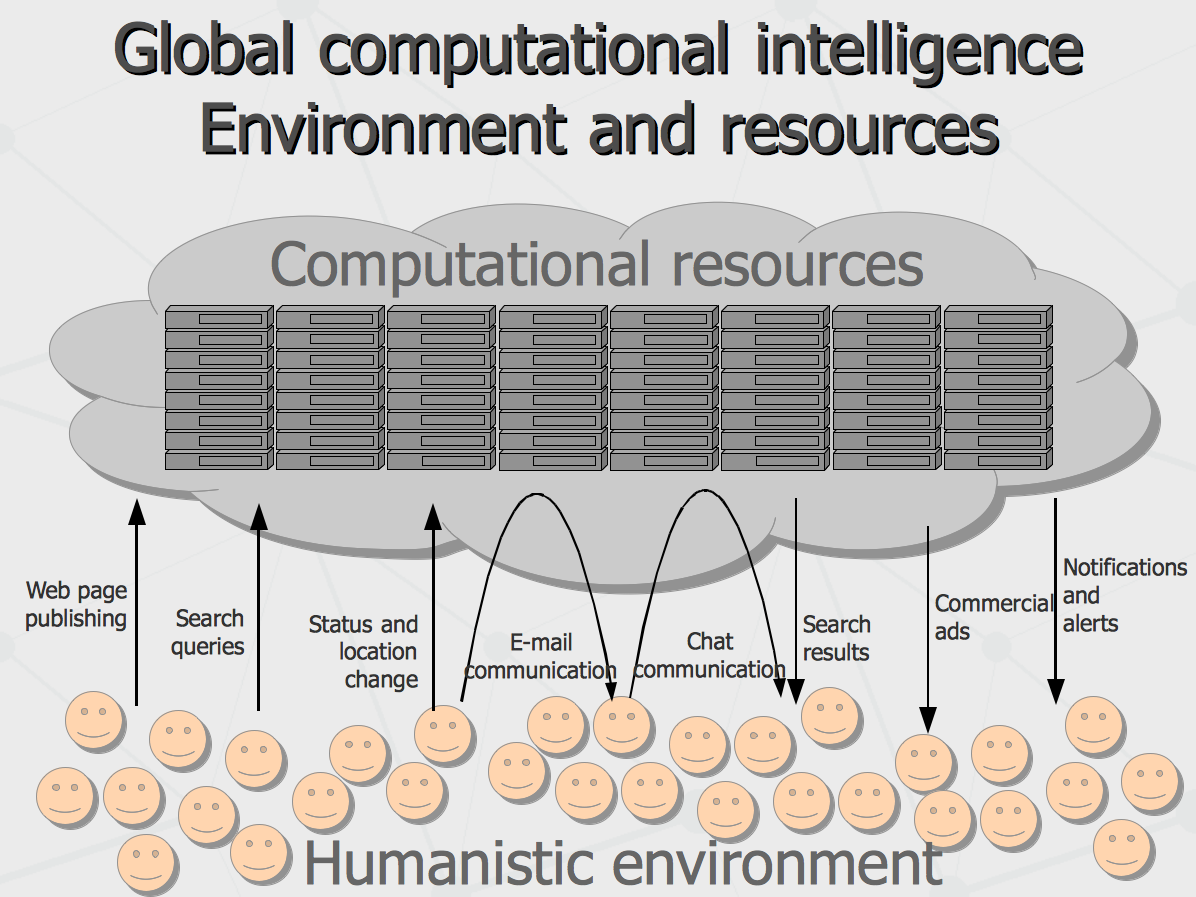
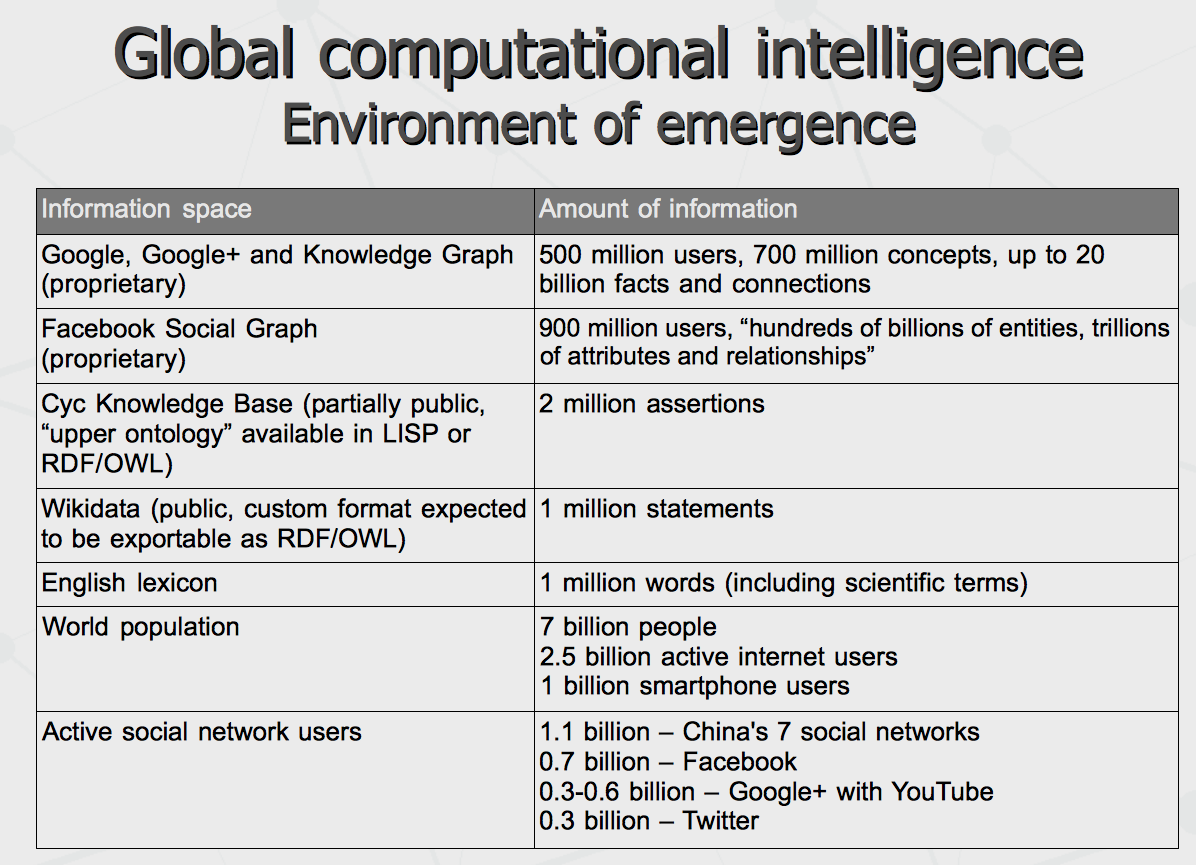
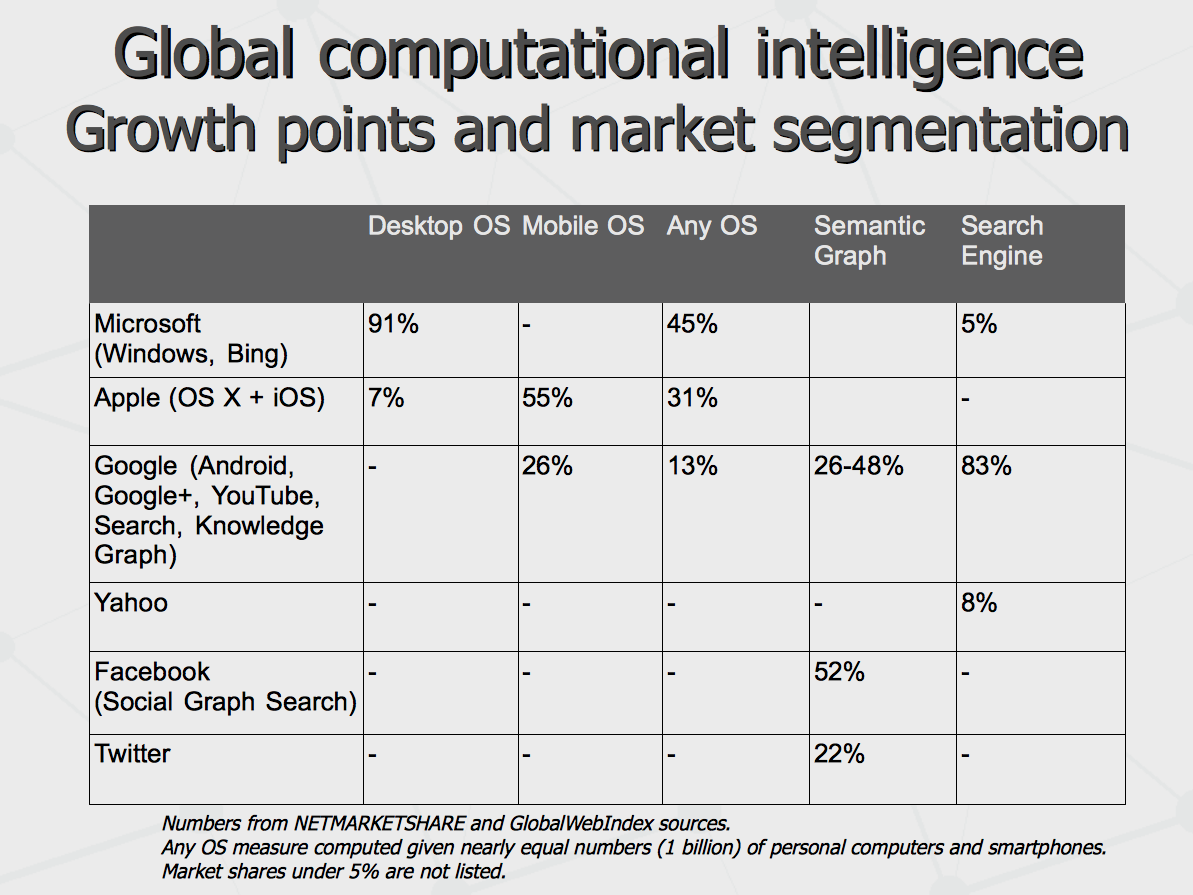
Few billion active internet users upload their pages and status messages, express their desires and wishes with search queries, report their locations – addressing all that to the system explicitly. They can also upload their day-to-day and minute-to-minute live experiences implicitly, by means of chat messages or emails transferred through the cloud mail or messaging providers. In response, the users are getting search results, replies and notifications, which correspond the queries but also have some mix-up of the content, driven by the goals of the entire system (posed by the business owner). Effectively, many of us (users of Android smartphones and Chrome browsers – especially) have really good chances to obtain intellectual immortality, at least partial – in form of our mental and behavioral models associated with our Google logins and reconstructed from our everyday activities. More than 10 years ago I worked in a team having a goal to build a working model of someone's psychic image to be mirrored by computer system. A lot of advances have been made since then. Last month, Google have re-hired the whole team of Behavio company, having some working model of the system, reconstructing behavioral model of smartphone user, relying on the flow of information coming through smartphone and all its sensors. Thus far, we are talking about non-humanoid intelligence emerging in humanistic environment. How rich is this environment and what are the computational resources available? First of all, let's take into account that computer intelligence of today is based on massive processing of structured information currently represented by semantic networks or graphs. We can see that since this year them most resourceful networks are owned by Google (Knowledge Graph) and Facebook (Graph Search). They contain more than billion vertices (nodes) and few order of magnitude more edges (links) – all accumulated during several past years. At the same time, the knowledge network collected by Cyc over more than 10 years is just about couple million vertices while publicly available Wikidata has 1 million only. For comparison, account that English lexicon with all scientific terms take same 1 million. Which leads to understanding that 99.9% of structured knowledge accumulated in the world may be about particular humans linked to Google and Facebook. That is, 1.5 billion people are involved in symbiosis with global computer system tightly and 1 billion people more is close to it. Interestingly, 7 social networks in China altogether have very good potential to beat each of the two US companies in terms of consolidation of the knowledge, if merged together (which is quite possible given the means Chinese administration possess).
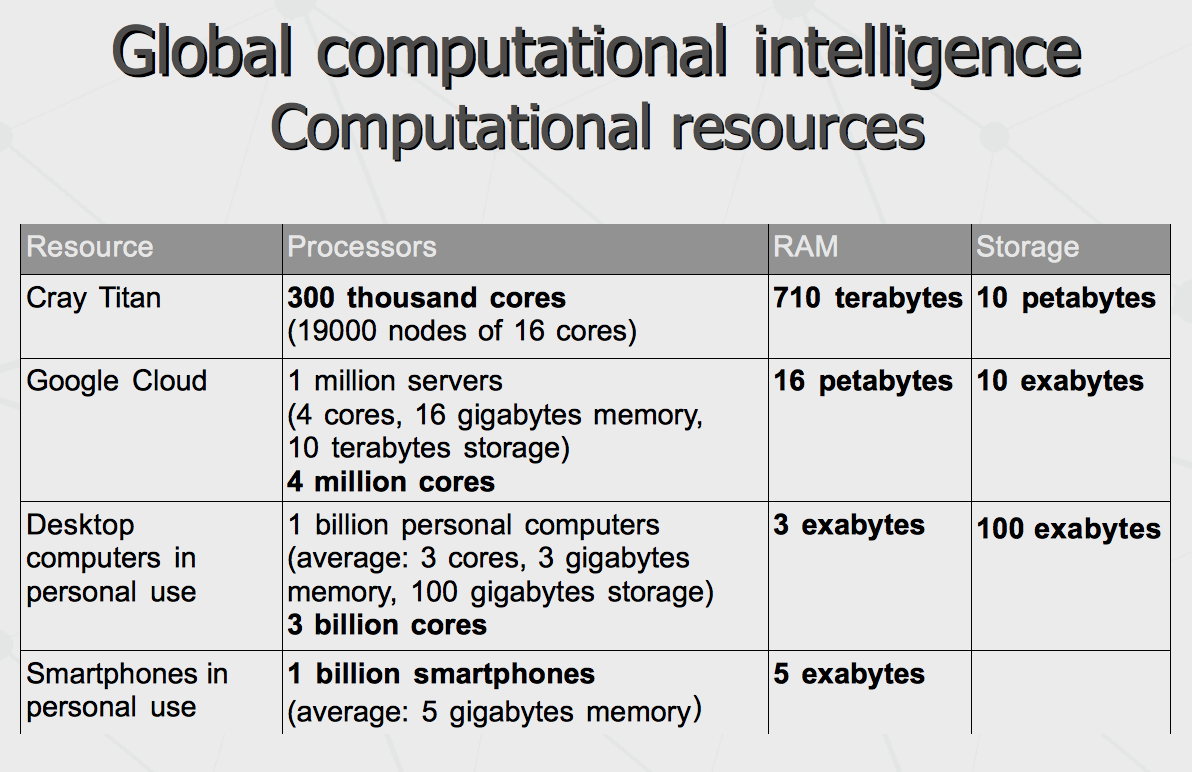
Further, let us see, which computational resources are involved. Rough estimations that could be collected over internet show that distributed computational power of Google's super-cloud exceeds the most powerful standalone super-computer by several orders of magnitude. In turn, computational power distributed across world population as personal computers and smartphones (not counting corporate hardware) exceeds the power of super-cloud mentioned above by the same several orders of magnitude. And this can give an idea that there is a room for further change and expansion.
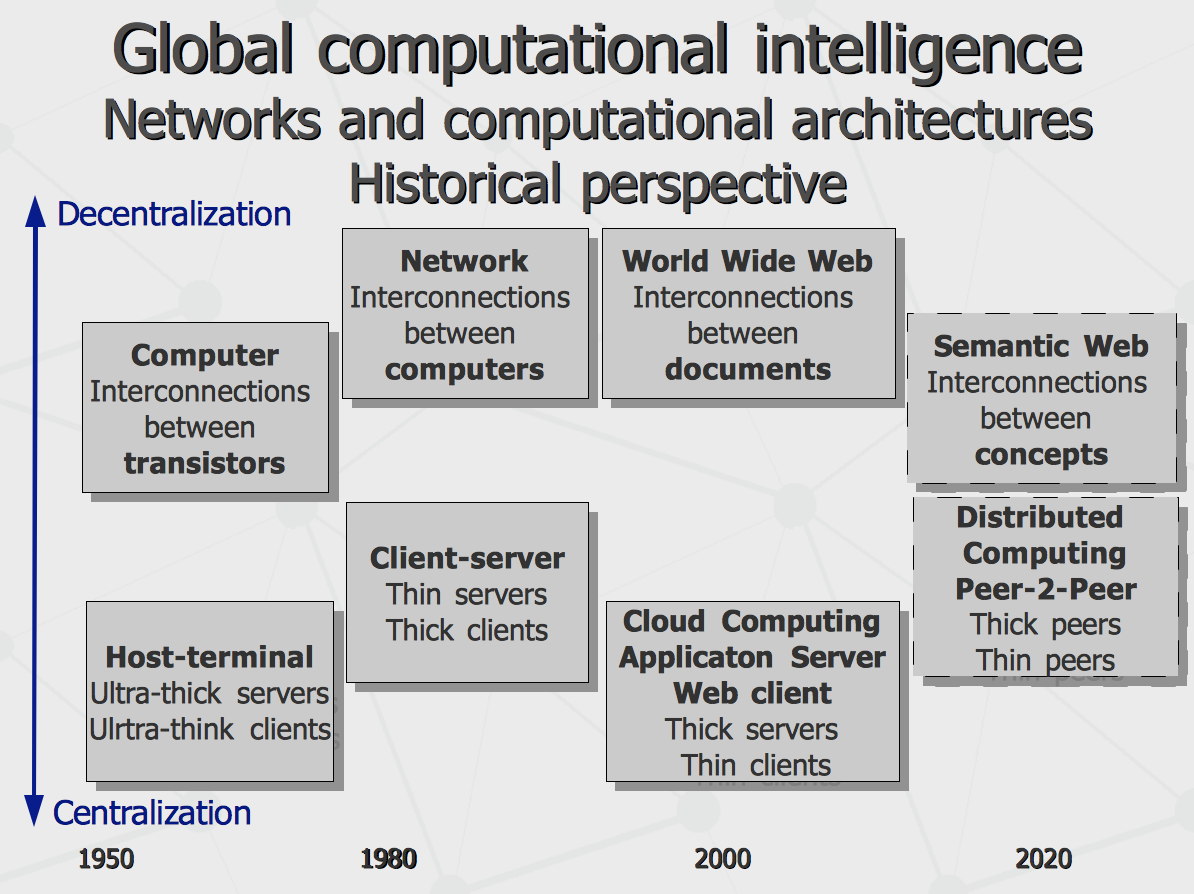
On the good side, there is a lot of stuff for free. Also, it seems like having all people in the world cross-linked together in one place is really quick path to have globalized social intelligence emerged in one or two sandboxes – for the benefit of the entire world society. Of course, the competitive advantages of the country hosting these sandboxes gets higher. On the other hand, “free cheese in mousetrap” historically has led to massive data loss for users of services like Yahoo Geocities (the most crowded online community by the end of past century) or say Google Wave. Then, given the situation with cyber-crime and governmental control of the data, there is no transparent way to assure privacy protection for the personal data processed by cloud service, especially – in jurisdiction of foreign country. Lastly, collapse of the world structured knowledge and its processing in one place, if locking out other paths of competitive evolution, impose certain risks of further development stagnation. If there is another way possible? Let's take a look at two historical perspectives on the following picture. Above, there is a version of the story (in terms of Piere Levi) telling what links what during the history of computing. As networks of transistors has evolved into network of computers, it is assumed that networks of documents will grow into network of concepts. However while change from to standalone computers to computer networks was a move from centralized processing to decentralized, originally distributed world wide web currently is experiencing collapse into world wide semantic net contained in single centralized storage. On the contrary, below is perspective of computer architectures evolution. From centralization/decentralization point of view, there is an up-and-down trend with centralized host-terminal systems replaced with “thick” clients (doing distributed processing) and “thin” file servers (just keeping the data). Then servers turned “thicker” into database servers and further application servers, having clients turned “thin” again. Finally, with AJAX clients and native mobile applications, the clients are becoming “thicker” again, still leaving a lot of “thickness” on the server side. So the two perspectives are in kind of misalignment at the moment.
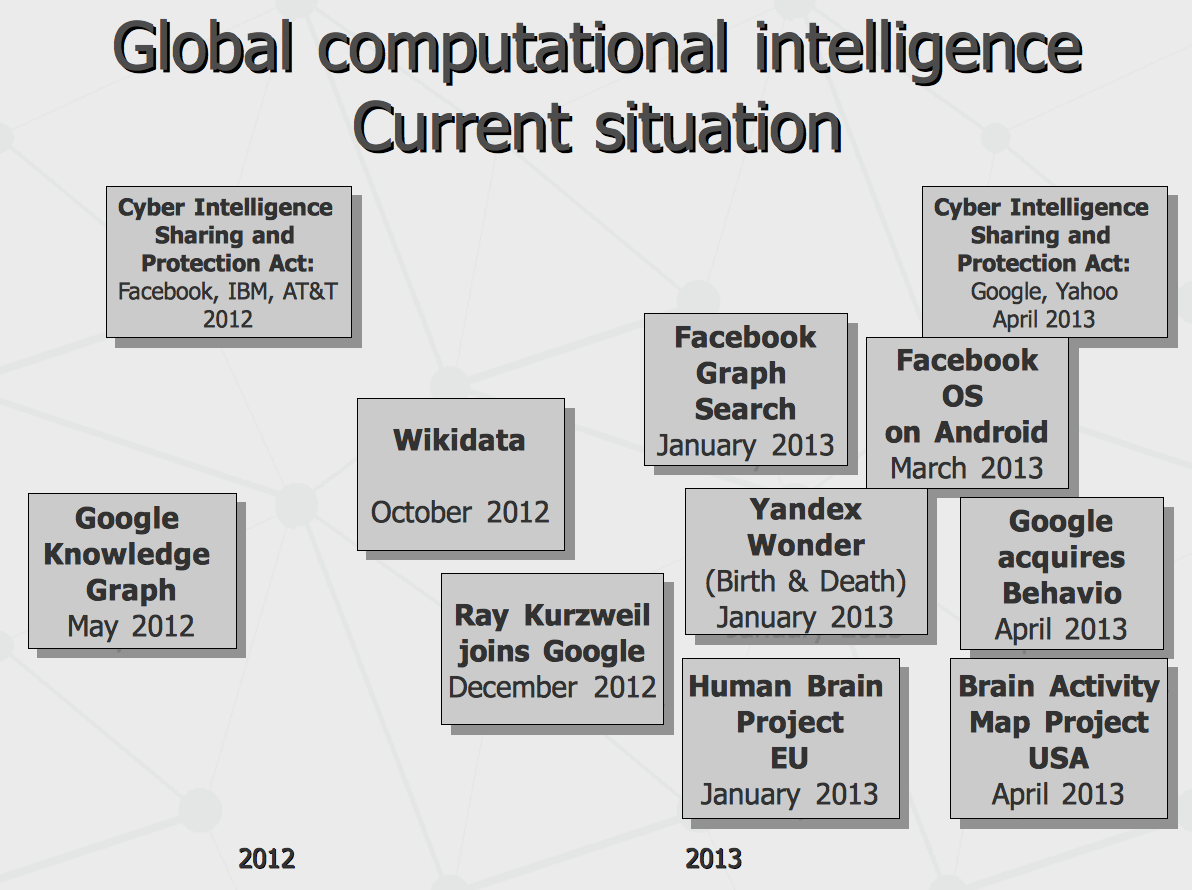
Indeed, evolution of human intelligence needed social interaction between human peers, which has been enabled with human society and language, which has been rocketed with globalized society and common language. Similarly, evolution of computer intelligence may need social interaction between computer peers, which could be enabled with computer society and language, preferably within global network and unified language. There has been more information on decentralized intellectual globalization model presented in my next presentation on "Distributed knowledge engineering" at the same forum. So, what have happened over the past year? Google Knowledge Graph has been announced less than year ago and half year later the Wikidata has been launched with help of Google to collect the structured knowledge from public for shared use. At the end of the year, Ray Kurzweil has joined the Google bringing his experience as pioneer in many of practical applications of artificial intelligence – with one of the missions to make real comprehension of human speech to happen. On the other frontier, same year, Facebook as well as few other major players have supported US government CISPA act granting access to personal data of the users – in order to assure national security. This year, Facebook has announced the challenge with its Graph Search competing with Google Knowledge Graph. Beginning this year, there has been attempt made by Yandex to provide an integrated client consolidating different social networks such as Facebook and Twitter – Facebook has closed API access to it almost instantaneously, seeing competitive treat in it. In its own turn, Facebook now is coming up with its own OS facade overloading Google Android user interface with Facebook functionality – so the sensory inputs (from some portion of those billion live sensors that we have mentioned above) can be re-directed from one computational brain to another. Back to Google, it supports the CISPA act (to be able to share private data with government) last month and hires the whole team of Behavio company so the behavioral models of any user can be built. Last week it announces its intellectual assistant Google Now on iOS to beat Apple's Siri. Finally, the CISPA act fails in US senate (but still is expected to be taken later as multiple pieces of legislation). Complementing the moves on computational and legal frontiers, on the science side, European union sets its flagship Human Brain project (to build full-blown artificial model of human brain) while US administration has promoted the BRAIN initiative (targeting to complete exhaustive mapping of human brain activity, as it had been done for human genome) – so the AI technology could be even more advanced in forthcoming years.
For a person – start feeling as part of the whole body or real-time sensor/motor cell of entire humanity organism, with every your search query, email, chat message or mouse click making it a bit more clever and strong, and every your action to some extent inspired by it. For software developers – get ready for emerging market of intellectual agent software (with first lonely players like Siri, Google Now and Sherpa), either keeping in mind business model of a «pilot fish», operating in biocenosis with one of the «Big Sharks» or having a good exit strategy for the case when your functionality may get on the way of some of major players (like it has happened to Yandex Wonder). For business – for competitive business promotion, understand how to craft «double-sided» web pages looking attractive for fellow people on one side and rich of true semantic markup on the other side. That kind of markup, invisible to human eye (see http://schema.org/ for more details) is to be indexed by «semantic crawler» at Google, collecting the thought-food for its Knowledge Graph — so that your site could get returned to user as single right answer on user's query, instead of being on 10th row of second page of search results. For government – be clear that ability to enable national projects of intellectual globalization might turn into a key for national security in the very close future. That does not necessarily mean any governmental funding of certain developments, as we have seen couple business enterprises managed to capture the third of the world in few years, so the most efficient option would be creation of appropriate business environments for high technology and information technology businesses within national borders. For humanity – get ready to pass through the next (since invention of computers and internet) pivotal point of development, with all coming surprises, frustrations and openings of new opportunities. For evolution – prepare to record forthcoming meta-system transition (since assembly of atoms in the molecule, molecules in the cell, cells into organism and neurons in the brain) in the Universe's diary book.
Appendices by author: Related reading: |